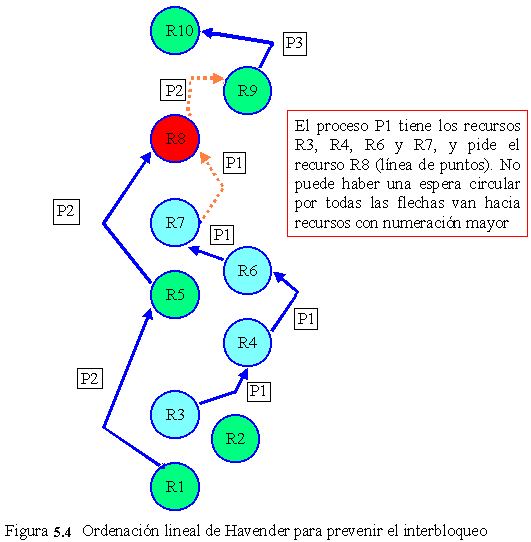
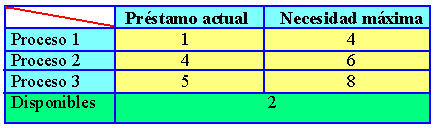
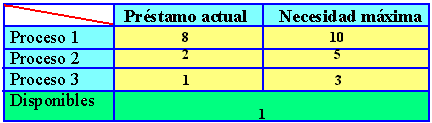
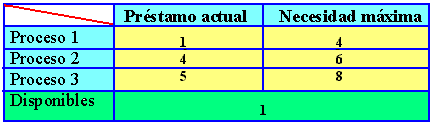
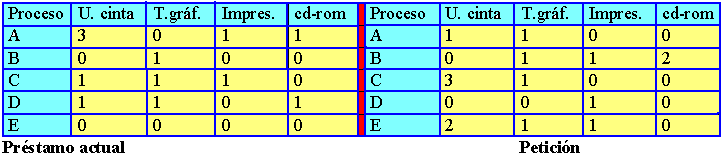
Figura 5.5 Algoritmo del banquero para múltiples recursos
La figura 5.5 representa dos matrices. La de la izquierda muestra el número de recursos asignados en ese instante (préstamo actual) a cada uno de los cinco procesos. En la derecha aparece el número de recursos que todavía necesita cada proceso para llevar a cabo su función (petición). Al igual que el caso de un único recurso, los procesos deben comunicar sus necesidades máximas antes de empezar a ejecutarse, de forma que en todo momento el sistema pueda calcular la matriz de la derecha.
Para describir los recursos existentes en el sistema, los que están en posesión y los que están disponibles, emplearemos tres vectores como los siguientes : E =(6342), P=(5322) y D=(1020). E indica que el sistema tiene 6 unidades de cinta, 3 trazadores, 4 impresoras y 2 cdrom. De ellos se están utilizando 5 unidades de cinta, tres trazadores gráficos, dos impresoras y dos cdrom. Esto se puede deducir sin más que sumar las cuatro columnas de recursos en préstamo de la matriz izquierda. El vector de recursos disponibles es simplemente la diferencia ente lo que el sistema tiene y lo que está usando en ese momento.
Ahora estamos en condiciones de describir en qué consiste el algoritmo de comprobación de estado seguro :
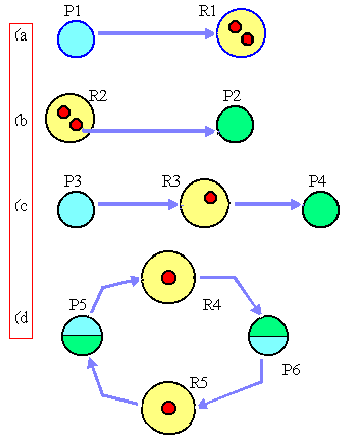
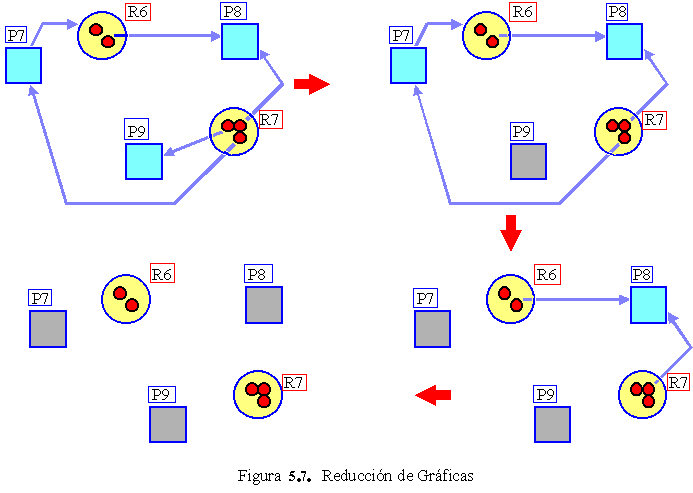
 1.-Buscar una fila, F, cuyas necesidades de recursos sean menores o iguales a D. Si no existe tal fila, el sistema puede interbloquearse, ya que ningún proceso puede ejecutarse hasta el final.
1.-Buscar una fila, F, cuyas necesidades de recursos sean menores o iguales a D. Si no existe tal fila, el sistema puede interbloquearse, ya que ningún proceso puede ejecutarse hasta el final.
2.-Suponer que el proceso de la fila seleccionada solicita todos los recursos que necesita, y termina. Marcar el proceso como terminado y añadir sus recursos al vector D.
3.-Repetir las etapas 1 y 2 hasta que se vayan marcando todos los procesos como terminados (en cuyo caso el estado inicial era seguro) o hasta que se llegue a una situación de interbloqueo (en cuyo caso no lo era).
En el caso de que se pueda seleccionar más de un proceso en el paso 1, la elección sería indiferente: en cualquier caso, el conjunto de recursos disponibles aumenta o, en el peor de los casos, se queda igual.
Volviendo al ejemplo de la figura 5.5 . El estado actual es seguro. Supongamos que el proceso B solicita la impresora. Dado que el estado resultante es todavía seguro, esta petición puede concederse (el proceso D puede terminar, seguido por los procesos A o E y a continuación el resto).
Imaginemos ahora que, después de que B obtiene una de las dos impresoras restantes, E solicita la última impresora. Si se le concede esta petición, el vector de recursos disponibles se reduciría a (1 0 0 0), situación que produce interbloqueo. Por lo tanto, la petición de E debe posponerse de momento.
Ahora debe estar claro cómo opera el algoritmo del banquero de Dijkstra cuando asigna recursos. Están permitidas las condiciones de espera circular, espera y no apropiación, pero los procesos sí exigen el uso exclusivo de los recursos que requieren. Los procesos pueden conservar recursos mientras piden y esperan recursos adicionales y los recursos no pueden arrebatarse a los procesos que los tienen. Los procesos facilitan el trabajo al sistema pidiendo un solo recurso a la vez. El sistema puede satisfacer o rechazar cada petición. Si una petición es rechazada, el proceso conserva los recursos que ya tiene asignados y espera un tiempo finito a que se satisfaga la petición. El sistema sólo satisface peticiones que llevan a estados seguros. Una petición que condujese a un estado inseguro se rechazaría repetidamente hasta que pueda quedar satisfecha. Como el sistema se mantiene en un estado seguro, tarde o temprano (en un tiempo finito) todas las peticiones podrán ser atendidas y los procesos terminarán.