En nuestra presentación, la tasa de fallos no ha sido un problema serio, ya que, como máximo, hay un fallo de página por cada página cuando se hace referencia a ella por primera vez. Esto no es muy exacto. Considere que, si un proceso de 10 páginas sólo emplea la mitad de ellas, entonces la paginación por demanda ahorra la E/S necesaria para cinco páginas que nunca se usarán. Podemos aumentar el nivel de multiprogramación ejecutando el doble de procesos. Así, si tuviéramos 40 marcos, podríamos ejecutar ocho procesos, en lugar de cuatro.
Si aumentamos nuestro nivel de multiprogramación, estamos sobreasignando la memoria. Si ejecutamos seis procesos, cada uno con un tamaño de 10 páginas, pero que sólo utilizan cinco, tenemos mayor utilización de la CPU y productividad, con diez marcos de sobra. Sin embargo, es posible que cada uno de estos procesos, para un conjunto de datos en particular, requiera sus 10 páginas, lo que supondría una necesidad de 60 marcos cuando tan sólo se dispone de 40. Aunque esta situación puede ser poco probable, la posibilidad aumenta con el nivel de multiprogramación. Puede, entonces, darse el caso de que produzcan demanda de páginas para las que no hay marcos. El sistema operativo podría abortar el proceso de usuario, pero la paginación dejaría de ser transparente, ya que, por razones desconocidas para el usuario se ha acabado con la ejecución de su proceso.
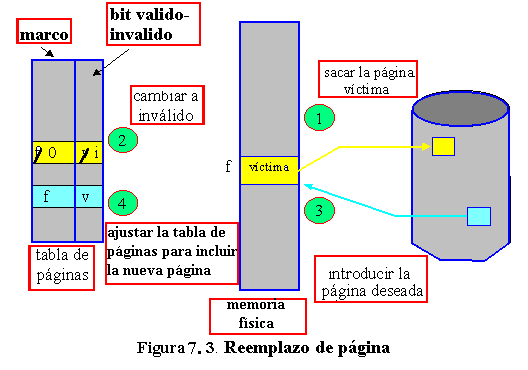
La solución está en reemplazar páginas. Si no hay ningún marco libre, encontramos uno que no se esté utilizando en ese momento y lo liberamos. Podemos liberar un marco escribiendo en disco todo su contenido y modificando la tabla de páginas (y todas las demás tablas) para indicar que la página ya no se encuentra en memoria (figura 7.3). El marco liberado puede usarse ahora para contener la página por la que falló el proceso. Ahora se modifica la rutina de servicio de fallo de página para incluir el reemplazo de página:
![]() Encontrar la ubicación en disco de la página deseada.
Encontrar la ubicación en disco de la página deseada.
![]() Buscar un marco libre:
Buscar un marco libre:
![]() Si hay un marco libre, utilizarlo.
Si hay un marco libre, utilizarlo.
![]() De lo contrario, utilizar un algoritmo de reemplazo de página con el fin de seleccionar un marco víctima.
De lo contrario, utilizar un algoritmo de reemplazo de página con el fin de seleccionar un marco víctima.
![]() Escribir la página víctima en disco; ajustar las tablas de marcos y páginas.
Escribir la página víctima en disco; ajustar las tablas de marcos y páginas.
![]() Leer la página deseada en el nuevo marco libre; modificar las tablas de páginas y marcos.
Leer la página deseada en el nuevo marco libre; modificar las tablas de páginas y marcos.
![]() Reanudar el proceso de usuario.
Reanudar el proceso de usuario.
Si no quedan marcos libres, se requieren dos transferencias de páginas (una de entrada y otra de salida). Esta situación duplica el tiempo de servicio de fallo de página y en consecuencia aumentará el tiempo efectivo de acceso.
Este tiempo de procesamiento adicional se puede reducir utilizando un bit de modificación (dirty bit). Cada página o marco puede tener asociado un bit de modificación en el hardware. El hardware pone a uno el bit de modificación para una página cuando en ella se escribe una palabra o un byte, indicando que ha sido modificada. Cuando seleccionamos una página para reemplazo, examinamos su bit de modificación. Si está activo, sabemos que la página se debe escribir en disco. Esta técnica también se aplica a páginas de sólo lectura. Con esto se reduce a la mitad el tiempo de E/S, si la página no ha sido modificada.
Para implantar la paginación por demanda debemos resolver dos grandes problemas: desarrollar un algoritmo de asignación de marcos y un algoritmo de reemplazo de páginas. Si tenemos varios procesos en memoria, debemos decidir cuántos marcos asignar a cada uno. Además, cuando se requiere un reemplazo de página es necesario seleccionar los marcos que se reemplazarán. El diseño de algoritmos adecuados para resolver estos problemas es una tarea importante, ya que la E/S de disco es muy costosa. Un pequeña mejora en los métodos de paginación por demanda produce amplias ganancias en el rendimiento del sistema.
7.4.1 Algoritmos de reemplazo [SILB94] [DEIT93] [STAL95]
Estamos buscando algoritmos que presenten la menor tasa de fallos de página. Para ello, necesitamos evaluarlos para una serie determinada de referencias a memoria y calcular el número de fallos de página. Podemos generar las cadenas de referencias aleatoriamente o bien coger una muestra del sistema. Esto producirá un gran número de datos (alrededor de un millón de referencias por segundo). Se puede reducir este número, ya que tan sólo hemos de considerar el número de páginas y no toda la dirección. Y además, si tenemos una referencia a una página p, entonces ninguna referencia a la página p que se presente inmediatamente después provocará fallo de página. La página p, ya se encuentra en memoria y las siguiente referencias a ella no provocan fallo de página.
Por ejemplo, si rastreamos un proceso, podemos anotar la siguiente secuencia de direcciones: 0100, 0432, 0101, 0612, 0102, 0103, 0104, 0101, 0611, 0102, 0103, 0104, 0101, 0610, 0102, 0103, 0104, 0609, 0102, 0105, lo cual, a 100 bytes por página, se reduce a la siguiente serie de referencias: 1, 4, 1, 6, 1, 6, 1, 6, 1, 6, 1.
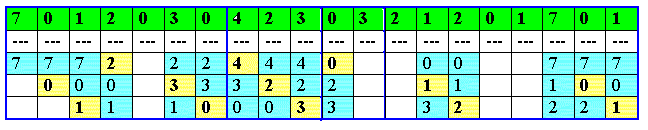
Para determinar el número de fallos de página para una serie de referencias y un algoritmo de reemplazo de página, necesitamos también el número de marcos de página por proceso. Si aumenta el numero de marcos, se reducirá el número de fallos de página. Para ilustrar los algoritmos de reemplazo de páginas, usaremos la siguiente secuencia de referencias 7, 0, 1, 2, 0, 3, 0, 4, 2, 3, 0, 3, 2, 1, 2, 0, 1, 7, 0, 1.
7.4.1.1 Reemplazo FIFO
El algoritmo de reemplazo más sencillo es el primero en entrar, primero en salir. Este algoritmo asocia a cada página el instante en el que se trajo a memoria. Cuando hay que reemplazar una página, se elige la más antigua. Para la cadena de referencias de ejemplo, y suponiendo un total de tres marcos, aplicamos este algoritmo con el resultado de 15 fallos de página.
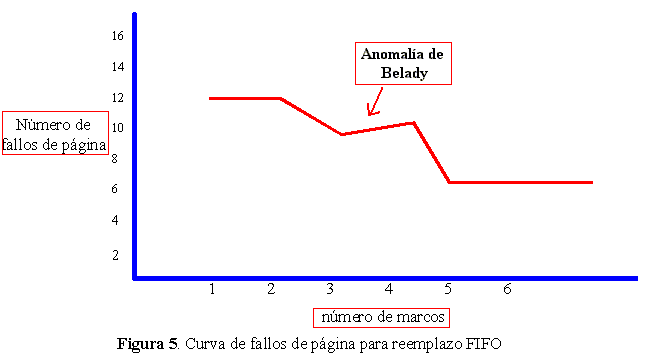
El algoritmo FIFO es fácil de comprender y programar, pero su rendimiento no siempre es bueno. La página reemplazada puede ser un módulo de asignación de valores iniciales que se utilizó hace mucho tiempo y que ya no se necesita. Pero también puede contener una variable cuyo valor inicial se asignó hace tiempo pero que se utiliza constantemente. Además, este algoritmo presenta una irregularidad denominada anomalía de Belady. Para ilustrarlo suponga que ahora tenemos la siguiente serie de referencias 1, 2, 3, 4, 1, 2, 5, 1, 2, 3, 4, 5. La figura 7.5 muestra la curva de fallos de páginas frente al número de marcos disponibles. Sorprendentemente el número de fallos para cuatro marcos (diez) es mayor que para tres marcos (nueve). Esto significa que con el algoritmo FIFO la tasa de fallos pueden aumentar al incrementar el número de marcos asignados.
7.4.1.2 Reemplazo Optimo
Una consecuencia del descubrimiento de la anomalía de Belady fue la búsqueda de un algoritmo de reemplazo de páginas óptimo. El algoritmo de reemplazo de páginas óptimo sería aquel que eligiera la página de la memoria que vaya a ser referenciada más tarde (con el ejemplo anterior vemos que se producen tan sólo 9 fallos de página). Si se elige otra, se producirá una falta de página antes, con lo que baja el rendimiento del sistema. Por desgracia, este algoritmo es irrealizable, pues no hay forma de predecir qué páginas referenciará un proceso en el futuro. Como resultado de esto, el algoritmo óptimo se utiliza sobre todo para estudios comparativos. Puede ser útil para saber que un nuevo algoritmo está dentro de 12.3% de lo óptimo en el peor de los casos y dentro del 4.7% en promedio.
7.4.1.3 Reemplazo Menos Recientemente Usado o LRU (Least Recently Used)
La principal diferencia entre los algoritmos FIFO y OPT es que el primero utiliza el instante en que entró una página en memoria, y el segundo, utiliza el tiempo en el que se usará la página. Una buena aproximación al algoritmo óptimo se basa en el principio de localidad de referencia de los programas. Las páginas de uso frecuente en las últimas instrucciones se utilizan con cierta probabilidad en las siguientes instrucciones. De manera recíproca, es probable que las páginas que no hayan sido utilizadas durante mucho tiempo permanezcan sin ser utilizadas durante cierto tiempo. Es decir, estamos utilizando el pasado reciente como aproximación de lo que sucederá en el futuro. El algoritmo LRU explota esta idea: al ocurrir un fallo de página se utiliza la página que no haya sido utilizada hace más tiempo. El resultado de aplicar este algoritmo a nuestro ejemplo produce 12 fallos.

Aunque LRU es realizable teóricamente, su implantación presenta problemas. Sería necesario mantener una lista enlazada de todas las páginas en la memoria, en donde la página de uso más reciente esté al principio de la lista y la de uso menos reciente al final. La dificultad estriba en que la lista debe actualizarse en cada referencia a la memoria. La búsqueda de una página en la lista, su eliminación y posterior traslado al frente de la misma puede ser una operación que consuma mucho tiempo. Es preciso un hardware especial (caro), o bien determinar una solución aproximada mediante software.
La búsqueda y manipulación de una lista enlazada en cada instrucción es prohibitiva por su lentitud, aún en hardware. Sin embargo, existen otras formas de implantar LRU con un hardware especial. Consideremos primero el caso más sencillo. Este método requiere un contador especial de 64 bits, C, en hardware, que se incrementa de forma automática después de cada instrucción. Además, cada entrada de la tabla de páginas debe tener un campo de tamaño adecuado como para contener al contador. Después de cada referencia a la memoria, el valor actual de C se almacena en la entrada de la tabla de páginas correspondiente a la página a la que se hizo referencia. Al ocurrir un fallo de página, el sistema operativo examina todos los contadores de la tabla de páginas y elige el mínimo. Esa página es la de utilizada menos recientemente.
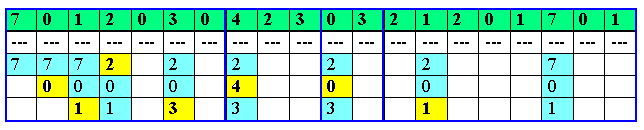
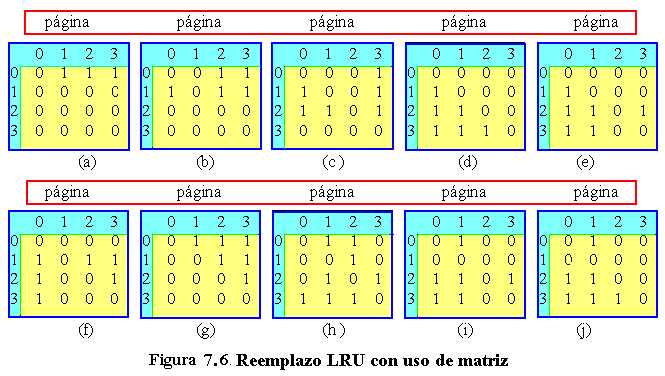
Analicemos ahora un segundo algoritmo LRU en hardware. En una máquina con n marcos, el hardware LRU puede utilizar una matriz de nxn bits, cuyos datos iniciales son todos cero. En una referencia al marco k, el hardware primero activa todos los bits del renglón k y desactiva después todos los bits de la columna k. En cualquier instante, la fila cuyo valor en binario es mínimo es el marco utilizado menos recientemente, la fila con el siguiente valor más pequeño es el segundo marco utilizado menos recientemente, etc. El funcionamiento de este algoritmo aparece en la figura 6 para cuatro marcos con referencias a los marcos en el orden:
![]() 0 1 2 3 2 1 0 3 2 3
0 1 2 3 2 1 0 3 2 3
Después de hacer referencia al marco 0 tenemos la situación de la figura 7.6 (a), etc.
Ni el reemplazo óptimo ni el reemplazo LRU padecen la anomalía de Belady. Los algoritmos de reemplazo denominados algoritmos de pila nunca presentan esta anomalía. Un algoritmo de pila es aquel que para el cual se puede demostrar que el conjunto de páginas en memoria para n marcos es siempre un subconjunto del conjunto de las páginas que estarían en memoria con n + 1 marcos. Para el reemplazo LRU, el conjunto de páginas en memoria sería las n páginas más recientemente usadas. Si el numero de marcos aumentara, estas n páginas seguirían siendo las de más reciente referencia y, por tanto, seguirían en memoria.
7.4.1.4 Aproximaciones a LRU.
Pocos sistemas proporcionan suficiente ayuda del hardware para un verdadero reemplazo de páginas LRU. Sin embargo, muchos sistemas ofrecen cierta ayuda, en la forma de un bit de referencia. El hardware coloca a uno el bit de referencia para una página cada vez que se hace una referencia a ella. Los bits de referencia están asociados a cada entrada de la tabla de páginas.
En principio, el sistema operativo borra todos los bits. Al ejecutarse un proceso de usuario, el hardware activa (asignando 1) el bit asociado a cada página referenciada. Después de cierto tiempo, examinando los bits de referencia podemos determinar qué páginas se han utilizado y cuáles no, aunque no sabemos el orden de uso. Esta información parcial de la ordenación nos lleva a varios algoritmos de reemplazo de páginas que se aproximan al LRU.
Algoritmos de bits Adicionales de Referencia
Podemos obtener información adicional de la ordenación anotando los bits de referencia a intervalos regulares. En una tabla en memoria podemos conservar ocho bits para cada página. A intervalos regulares (cada 100 milisegundos), una interrupción del cronómetro transfiere el control al SO. El sistema operativo desplaza el bit de referencia de cada página al bit de orden superior de sus ocho bits, desplazando los otros bits una posición a la derecha y descartando el bit de orden inferior. Estos registros contienen la historia de la utilización de la página durante los últimos ocho periodos. Si el registro de desplazamiento contiene 00000000, entonces la página no ha sido utilizado en ocho periodos; una página que se utiliza por lo menos una vez cada periodo tendría un valor 11111111 en su registro de desplazamiento.
Una página con valor 11000100 ha sido utilizada más recientemente que una con valor 01110111. Interpretando estos bits como enteros sin signo, la página con el menor número es la que se debe reemplazar. El número de bits históricos puede variar. En el caso extremo, el número puede reducirse a cero, dejando únicamente el bit de referencia. A esta versión se le llama algoritmo de reemplazo de la segunda oportunidad.
El algoritmo de la Segunda Oportunidad
Una modificación simple de FIFO, que evita deshacerse de una página de uso frecuente, inspecciona el bit R de la página más antigua. Si es 0, la página es antigua y no utilizada, por lo que se reemplaza de manera inmediata. Si el bit es 1, R se pone a cero, la página se coloca al final de la lista de páginas, como si hubiera llegado en ese momento a la memoria. Después continúa la búsqueda siguiendo la lista.
La operación de este algoritmo, llamado de la segunda oportunidad, se muestra en la figura 7.7. En la figura 7.7 (a), vemos las páginas de la A a la H, en una lista enlazada ordenada según el tiempo de llegada a la memoria.
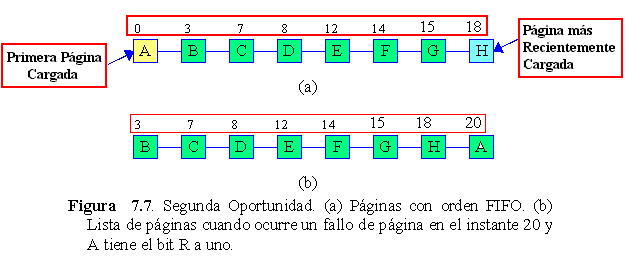
Lo que hace el algoritmo de la segunda oportunidad es buscar una página antigua sin referencias, si todas las páginas tienen alguna referencia deviene en un simple FIFO. En efecto, supongamos que todas las páginas de la figura 7.7 (a) tienen R a 1. Una a una, el sistema operativo traslada las páginas al final de la lista y pone su bit R a cero. Al final, se vuelve a la página A, la cual tiene R a cero. En este momento, A se retira de la memoria. Por lo tanto, el algoritmo siempre termina.
El Algoritmo del Reloj
Aunque la segunda oportunidad es un algoritmo razonable, es ineficiente e innecesario, puesto que desplaza las páginas en una lista. Un mejor diseño consiste en mantener las páginas en una lista circular, con la forma de un reloj, como se muestra en la figura 7.8. Una manecilla apunta hacia la página más antigua.
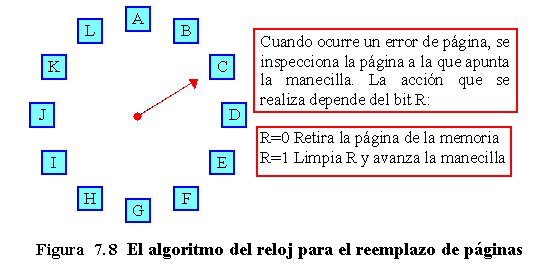
Al ocurrir un fallo de página, se inspecciona la página a la que apunta la manecilla. Si su bit R vale 0, la página se retira de la memoria, se inserta la nueva página en su lugar en el reloj, y la manecilla avanza una posición. Si R vale 1, este bit se pone a 0 y la manecilla avanza a la página siguiente. Este proceso continúa hasta encontrar una página con R a cero. Este algoritmo sólo difiere del anterior en su implementación.
Algoritmo LFU (Last Frequently Used)
Un algoritmo de reemplazo de página menos frecuentemente usada (Least Frequently Used) mantiene un contador del número de referencias que se han hecho para cada página. Se reemplaza la página con el menor recuento. La razón para esta selección es que una página que se usa activamente debe tener un alto número de referencias. Este algoritmo tiene problemas cuando una página se usa mucho en la fase inicial de un proceso, pero después ya no se utiliza. Como se usó bastantes veces, tiene un recuento alto y permanece en memoria aunque ya no se necesite. Una solución consiste en desplazar los recuentos un bit a la derecha a intervalos regulares, formando un recuento promedio de utilización que disminuye exponencialmente.
El algoritmo MFU (Most Frequently Used)
Otro algoritmo de reemplazo de páginas es el reemplazo más frecuentemente usado, que se basa en el argumento de que la página con el menor recuento probablemente acaba de llegar y aún tiene que usarse. Como se podría esperar, no es común ni el reemplazo MFU ni el LFU porque son costosos y se alejan mucho del reemplazo OPT.
Algoritmo de páginas de uso no reciente o NRU (Not Recently Used)
La mayoría de los ordenadores presentan los bits R (de referencia) y M (de modificación) en las entradas de la tabla de páginas, siendo estos bits actualizados vía hardware. Si el hardware no proporciona dichos bits, éstos pueden ser simulados mediante el software. Para ello, cuando se inicia un proceso se señalan todas sus entradas en la tabla de páginas como si no estuvieran dentro de la memoria. Si se hace referencia a cualquier página, ocurre un fallo de página. El sistema operativo activa entonces el bit R (en sus propias tablas) y cambia la entrada de la tabla de páginas para que apunte hacia la página correcta, poniendo dicha entrada en modo sólo lectura (recordar los bits de permisos). El proceso retoma su ejecución; si se escribe en la página, ocurre otra interrupción por violación de permisos, lo que permite al sistema operativo activar el bit M en sus tablas, cambiando los permisos de la página a lectura y escritura.
Disponiendo de los citados bits R y M se puede construir el siguiente algoritmo: al iniciar un proceso, el sistema operativo asigna un valor 0 a los bits R y M de todas sus páginas. De manera periódica (cada interrupción del reloj) se pone a cero el bit R, para distinguir las páginas que no tienen referencias recientes de las que sí.
Ante un fallo de página, el sistema operativo inspecciona todas las páginas y las divide en cuatro categorías, según los valores actuales de los bits R y M:
![]() Clase 0:no referenciada, ni modificada (0,0).
Clase 0:no referenciada, ni modificada (0,0).
![]() Clase 1:no referenciada, pero modificada (0,1).
Clase 1:no referenciada, pero modificada (0,1).
![]() Clase 2:referenciada, pero no modificada (1,0).
Clase 2:referenciada, pero no modificada (1,0).
![]() Clase 3:referenciada y modificada (1,1).
Clase 3:referenciada y modificada (1,1).
Aunque parece imposible la existencia de las páginas de la clase 1, este caso aparece cuando en una página de clase 3, una interrupción del reloj pone a cero su bit R. Las interrupciones del reloj no provocan el poner a cero el bit M, puesto que esta información es necesaria para saber si hay que volver a escribir la página en el disco o no.
El algoritmo NRU elimina una página de manera aleatoria de la primera clase no vacía con el número más pequeño. Una hipótesis implícita de este algoritmo es que es mejor eliminar una página modificada sin referencias en al menos un intervalo del reloj (por lo general, de 20 mseg) que una página sin modificar de uso frecuente. Este algoritmo es fácil de comprender, tiene una implementación eficiente y un rendimiento aceptable.
7.4.1.5 Asignación Global frente a Asignación Local [SILB94]
Cuando varios procesos compiten por marcos podemos clasificar los algoritmos de reemplazo de páginas en dos categorías: reemplazo global y reemplazo local. El reemplazo global permite que un proceso seleccione un marco para reemplazar de entre todo el conjunto de marcos, incluso si ese marco está asignado a otro proceso; un proceso puede quitar un marco a otro. El reemplazo local requiere que cada proceso selecciones sólo de su propio conjunto de marcos asignados.
Con una estrategia de reemplazo local, el número de marcos asignados a un proceso no cambia. Con el reemplazo global es posible que un proceso sólo seleccione marcos que pertenezcan a otros procesos, incrementando su número de marcos asignados (suponiendo que otros procesos no elijan sus marcos para reemplazo).
Un problema del algoritmo de reemplazo global es que un proceso no puede controlar su propia tasa de fallos de página. El conjunto de páginas en memoria para un proceso no sólo depende del comportamiento de paginación de ese proceso, sino también del de los otros. Por tanto, puede variar la forma en que se ejecuta un proceso debido a circunstancias totalmente ajenas. Esto no ocurre con un algoritmo de reemplazo local. Con este esquema, el conjunto de páginas en memoria para ese proceso sólo depende de su comportamiento en cuanto a paginación. Ahora bien, el reemplazo local impide a un proceso tener acceso a otras páginas de memoria menos usadas. Por esta razón, el reemplazo global generalmente brinda una mayor productividad.