
Un sistema de paginación por demanda es similar a un sistema de paginación con intercambios. Los procesos residen en memoria secundaria (en el disco). Cuando queremos ejecutar un proceso, lo metemos en memoria. Sin embargo, en vez de intercambiar todo el proceso hacia la memoria, utilizamos un intercambiador perezoso. Un intercambiador perezoso nunca reincorpora una página a memoria a menos que se necesite. Como ahora consideramos un proceso como una secuencia de páginas, en vez de un gran espacio contiguo de direcciones, el término intercambio es técnicamente incorrecto. Un intercambiador manipula procesos enteros, mientras que un paginador trata con las páginas individualmente de un proceso.
Cuando un proceso se reincorpora, el paginador lleva a memoria las páginas necesarias. Así evita colocar en la memoria páginas que no se utilizarán, reduciendo el tiempo de intercambio y la cantidad de memoria física necesaria.
Este esquema requiere apoyo del hardware. Generalmente se añade un bit más a cada entrada de la tabla de páginas: un bit válido-inválido. Cuando este bit está asignado como válido, indica que la página asociada se encuentra en memoria. Si el bit está como inválido, este valor indica que la página está en disco. Una página marcada como inválida no tendrá ningún efecto si el proceso nunca intenta acceder a esa página.
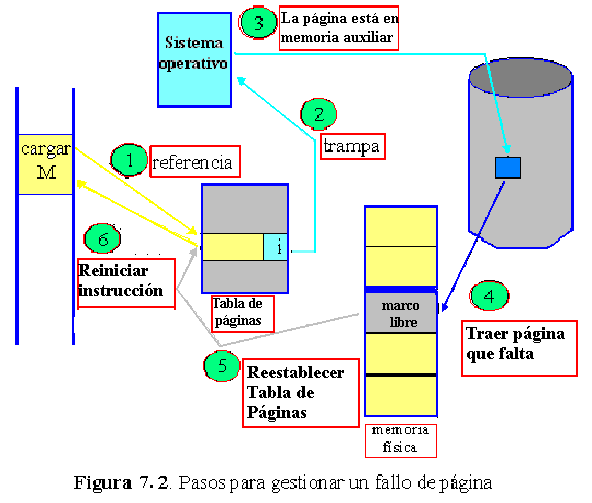
¿Pero qué sucede si el proceso trata de usar una página que no se incorporó a la memoria? Si adivinamos mal y el proceso trata de acceder a una página que no se trajo a memoria, ocurrirá una trampa de fallo de página. El hardware de paginación, al traducir la dirección mediante la tabla de páginas, observará que el valor del bit es inválido, generando una trampa para el sistema operativo (error de dirección no válido). Normalmente, un error de dirección no válida es consecuencia de intentar utilizar una dirección de memoria ilegal; en este caso, el proceso deberá terminar. Sin embargo, en esta situación la trampa es el resultado del fallo de página del sistema operativo al no transferir a memoria una parte válida del proceso, tratando de minimizar el tiempo adicional de transferencia de disco y los requisitos de memoria. Por tanto, debemos corregir esta omisión. El procedimiento es sencillo (figura 7.2):
![]() Consultamos una tabla interna (que por lo general se conserva en el PCB del proceso) para determinar si la referencia fue un acceso a memoria válido o inválido.
Consultamos una tabla interna (que por lo general se conserva en el PCB del proceso) para determinar si la referencia fue un acceso a memoria válido o inválido.
![]() Si fue inválido, abortamos el proceso. Si se trató de una referencia válida, pero aún no hemos traído la página, la incorporamos.
Si fue inválido, abortamos el proceso. Si se trató de una referencia válida, pero aún no hemos traído la página, la incorporamos.
![]() Encontramos un marco libre (por ejemplo, seleccionando uno de la tabla de marcos libres).
Encontramos un marco libre (por ejemplo, seleccionando uno de la tabla de marcos libres).
![]() Planificamos una operación para leer de disco la página deseada en el marco recién asignado.
Planificamos una operación para leer de disco la página deseada en el marco recién asignado.
![]() Cuando ha concluido la lectura de disco, modificamos la tabla interna que se conserva junto con el proceso y la tabla de páginas para indicar que ahora la página se encuentra en memoria.
Cuando ha concluido la lectura de disco, modificamos la tabla interna que se conserva junto con el proceso y la tabla de páginas para indicar que ahora la página se encuentra en memoria.
![]() Reiniciamos la instrucción interrumpida por la trampa de dirección ilegal. El proceso ahora puede acceder a la página como si siempre se hubiera encontrado en memoria.
Reiniciamos la instrucción interrumpida por la trampa de dirección ilegal. El proceso ahora puede acceder a la página como si siempre se hubiera encontrado en memoria.
Es importante observar que, como almacenamos el contexto del proceso (registros, código de condición, contador de instrucciones), interrumpido al ocurrir un fallo de página, podemos reanudarlo exactamente en el mismo punto y estado, excepto que ahora la página deseada se encuentra en memoria y se puede acceder a ella.
El caso más extremo es comenzar la ejecución de un proceso sin páginas en memoria. De inmediato, con la primera instrucción, el proceso presentaría una fallo de página. Después de traer de memoria esta página, el proceso continúa su ejecución, provocando fallos cuando sea necesario hasta que todas las páginas que necesita se encuentren en memoria. Esto es la paginación por demanda pura: no traer una página a memoria hasta que se requiera.
En teoría, algunos programas pueden acceder a una nueva página de memoria con cada instrucción que ejecutan, provocando posiblemente un fallo de página por cada instrucción. Esta situación provocaría un rendimiento inaceptable. Por fortuna, los análisis de procesos en ejecución han mostrado que esta situación es muy poco probable. Los programas suelen poseer una localidad de referencias (como veremos más adelante), que brinda un rendimiento aceptable en la paginación bajo demanda.
El hardware para apoyar la paginación bajo demanda es el mismo que se usa para la paginación y segmentación, y los intercambios:
![]() Tabla de páginas. Esta tabla tiene la capacidad para marcar una entrada como inválida usando un bit válido-inválido o un valor especial de los bits de protección.
Tabla de páginas. Esta tabla tiene la capacidad para marcar una entrada como inválida usando un bit válido-inválido o un valor especial de los bits de protección.
![]() Memoria secundaria. Esta memoria contiene las páginas que no se conservan en la memoria principal. La memoria secundaria casi siempre es un disco de alta velocidad.
Memoria secundaria. Esta memoria contiene las páginas que no se conservan en la memoria principal. La memoria secundaria casi siempre es un disco de alta velocidad.
Además de esta ayuda hardware, se requiere un considerable apoyo software, como veremos luego.
Hay que imponer algunas restricciones arquitectónicas. Un aspecto crítico es la capacidad para reiniciar cualquier instrucción después de un fallo de página. En la mayoría de los casos es fácil cumplir este requisito. Si falla la página al buscar la instrucción, podemos reiniciarla efectuando de nuevo la búsqueda. Si ocurre el fallo al buscar el operando, debemos buscar de nuevo la instrucción, decodificarla y luego buscar el operando.
Como el peor de los casos, considere una instrucción de tres direcciones como ADD (suma) de A y B, colocando el resultado en C. Los pasos para ejecutar esta instrucción serían
![]() Buscar y decodificar la instrucción ADD.
Buscar y decodificar la instrucción ADD.
![]() Buscar A.
Buscar A.
![]() Buscar B.
Buscar B.
![]() Sumar A y B.
Sumar A y B.
![]() Guardar el resultado en C.
Guardar el resultado en C.
Si se presentara un fallo al almacenar en C, tendríamos que obtener la página deseada, traerla a memoria, corregir la tabla de páginas y reiniciar la instrucción. Este inicio implica buscar de nuevo la instrucción, decodificarla, buscar una vez más los dos operandos y volver a sumar. Esto significa repetir la instrucción.
La principal dificultad surge cuando una instrucción puede modificar varias localidades distintas. Por ejemplo, considere una instrucción MVC (mover carácter), que puede mover hasta 256 bytes de una localidad a otra (que pueden coincidir parcialmente). Si alguno de los bloques (fuente o destino) sobrepasa un límite de página, puede ocurrir un fallo de página después de haber efectuado parte de la transferencia. Además, si los bloques fuente y destino se superponen es probable que se modifique el bloque fuente, por lo que no podríamos reiniciar la instrucción.
Este problema se resuelve de dos maneras. En una de las soluciones, el microcódigo calcula y trata de acceder a ambos extremos de los bloques. Si va a ocurrir una fallo de página, sucederá en esta etapa, antes de modificar algo. Entonces puede efectuarse la transferencia si sabemos que no ocurrirá ningún fallo de página, ya que todas las páginas en cuestión se encuentran en memoria. La otra solución utiliza registros temporales para contener los valores de las localidades sobreescritas. Si se presenta un fallo de página, todos los valores que había antes de que ocurriera la trampa regresan a la memoria. Esta acción restablece la memoria a su estado anterior a la ejecución de la instrucción, por lo que podemos repetir la instrucción.
Estos no son los únicos problemas arquitectónicos que pueden surgir al añadir paginación, pero sí ilustran sus dificultades. En los sistemas de computación, la paginación debe ser completamente transparente para el proceso de usuario.
3.1 Rendimiento de la Paginación por Demanda [SILB94]
La paginación por demanda puede tener un efecto considerable en el rendimiento de un sistema de computación. Para ver la razón, calculemos el tiempo de acceso efectivo para la memoria paginada por demanda. El tiempo de acceso a memoria, am, para la mayoría de los sistemas de computación actuales va de 10 a 200 nanosegundos. Mientras no tengamos fallos de página, el tiempo de acceso efectivo es igual al tiempo de acceso a memoria en un sistema paginado (que sería dos accesos a memoria, uno a la tabla de páginas y otro a la dirección de memoria). Sin embargo, si ocurre un fallo de página, primero debemos leer de disco la página indicada y luego acceder a la palabra deseada.
Sea p la probabilidad de un fallo de página (0 <= p => 1). Podemos esperar que p sea muy cercano a cero; es decir, que habrá sólo unas cuantos fallos de página. Entonces, el tiempo efectivo de acceso es:
![]() tiempo efectivo de acceso = (1-p) x am + p x tiempo de fallo de página
tiempo efectivo de acceso = (1-p) x am + p x tiempo de fallo de página
Para calcular este tiempo necesitamos saber cuánto tiempo se requiere para servir un fallo de página. Un fallo de página desencadena la siguiente secuencia:
![]() 1. Trampa para el sistema operativo.
1. Trampa para el sistema operativo.
![]() 2. Guardar el contexto del proceso.
2. Guardar el contexto del proceso.
![]() 3. Determinar si la interrupción fue un fallo de página.
3. Determinar si la interrupción fue un fallo de página.
![]() 4. Verificar que la referencia a la página haya sido legal y determinar la ubicación de la página en el disco.
4. Verificar que la referencia a la página haya sido legal y determinar la ubicación de la página en el disco.
![]() 5. Leer de disco a un marco libre:
5. Leer de disco a un marco libre:
![]() 5a. Esperar en la cola del dispositivo hasta que se atienda la solicitud de lectura.
5a. Esperar en la cola del dispositivo hasta que se atienda la solicitud de lectura.
![]() 5b. Esperar durante el tiempo de búsqueda y de latencia del dispositivo.
5b. Esperar durante el tiempo de búsqueda y de latencia del dispositivo.
![]() 5c.Comenzar la transferencia de la página al marco libre.
5c.Comenzar la transferencia de la página al marco libre.
![]() 6. Durante la espera, asignar la CPU a otro proceso (planificación).
6. Durante la espera, asignar la CPU a otro proceso (planificación).
![]() 7. Interrupción del disco de fin de la E/S.
7. Interrupción del disco de fin de la E/S.
![]() 8. Guardar el contexto del otro proceso.
8. Guardar el contexto del otro proceso.
![]() 9. Determinar si la interrupción provino de disco.
9. Determinar si la interrupción provino de disco.
![]() 10. Corregir la tabla de páginas y las demás tablas para indicar que la página deseada se encuentra en memoria.
10. Corregir la tabla de páginas y las demás tablas para indicar que la página deseada se encuentra en memoria.
![]() 11. Esperar que la CPU se asigne nuevamente a este proceso.
11. Esperar que la CPU se asigne nuevamente a este proceso.
![]() 12. Restablecer el contexto y la nueva tabla de páginas, y reanudar la instrucción interrumpida.
12. Restablecer el contexto y la nueva tabla de páginas, y reanudar la instrucción interrumpida.
Es posible que no sean necesarios todos los pasos para todos los casos. Por ejemplo, en el paso 5 suponemos que la CPU se asigna a otro proceso mientras se efectúa la E/S. Esta disposición permite que la multiprogramación mantenga la utilización de la CPU pero requiere tiempo adicional para reanudar la rutina de servicio del fallo de página cuando concluye la transferencia de E/S.
En cualquier caso, nos enfrentamos a tres componentes principales del tiempo de servicio del fallo de página:
![]() Servir la interrupción de fallo de página.
Servir la interrupción de fallo de página.
![]() Leer la página.
Leer la página.
![]() Reanudar el proceso.
Reanudar el proceso.
La primera y tercera tareas pueden reducirse a varios cientos de instrucciones. Estas tareas pueden costar de 1 a 100 microsegundos cada una. El tiempo de cambio de página, por otra parte, será cercano a los 24 milisegundos. Un disco de cabeza móvil tiene una latencia de 8 milisegundos, un tiempo de búsqueda de 15 milisegundos y un tiempo de transferencia de un milisegundo. Por tanto, el tiempo total de paginación será cercano a los 25 milisegundos, incluyendo tiempo de hardware y software. Recuerde que sólo consideramos el tiempo de servicio del dispositivo. Si una cola de procesos espera al dispositivo, tenemos que añadir el tiempo de cola mientras esperamos a que el dispositivo de paginación esté libre para atender nuestra solicitud, lo que incrementa aún más nuestro tiempo de intercambio.
Si tomamos como tiempo promedio de servicio de fallo de página 25 milisegundos y un tiempo de acceso a memoria total de 100 nanosegundos, entonces el tiempo efectivo de acceso, expresado en nanosegundos, es
![]() Tiempo efectivo de acceso = (1-p) x 100 + p x 25 miliseg =
Tiempo efectivo de acceso = (1-p) x 100 + p x 25 miliseg =
= (1-p) x 100 + p x 25000000 = 100 + 24999900 x p.
Vemos entonces que el tiempo efectivo de acceso es directamente proporcional a la tasa de fallos de página. Si un acceso de cada mil provoca un fallo de página, el tiempo de acceso efectivo es de 25 milisegundos. El computador sería 250 veces más lento debido a la paginación por demanda. Si queremos una degradación menor al 10%, necesitamos
110 > 100 + 25000000 x p,
10 > 25000000 x p,
![]() p < 0.0000004
p < 0.0000004
O sea, para mantener un nivel razonable de lentitud adicional provocada por la paginación por demanda, sólo podemos permitir que se tenga menos de un fallo de página por cada 2500000 accesos. Es muy importante mantener baja la tasa de fallos de página en un sistema de paginación por demanda; de lo contrario aumenta el tiempo efectivo de acceso, frenando considerablemente la ejecución de los procesos.
Otro aspecto de la paginación por demanda es el manejo y uso del espacio de intercambios. La E/S de disco para el espacio de intercambios generalmente es más rápida que con el sistema de ficheros. Esto es así porque se asigna espacio en bloques de mayor tamaño y no se usan las búsquedas de ficheros ni los métodos de asignación indirecta. Por tanto, es posible que el sistema obtenga una mejor productividad de la paginación copiando todo el contenido de un fichero al espacio de intercambios al iniciar el proceso, y luego efectuar la paginación por demanda desde el espacio de intercambios.