
4.5 Apéndice 1. Un ejemplo de aplicación cliente-servidor
En este apéndice vamos a ver cómo se pueden utilizar las primitivas de mensajes con designación directa proporcionadas por el sistema operativo para crear un servidor de ficheros, y un cliente que solicita sus servicios para copiar un fichero. Previamente se muestra cómo se puede realizar un programa que copie un fichero en un sistema en el que las operaciones con ficheros las proporciona el sistema operativo, y no un proceso de usuario como será el servidor de ficheros.
Copia de un fichero utilizando primitivas proporcionadas por el sistema operativo
Comencemos estudiando cómo realizar un programa sencillo en C para MS DOS que copia un fichero fuente a un fichero destino. El listado del programa es el siguiente:

El programa tiene una funcionalidad mínima y un informe de los errores raquítico. El programa copyfile se puede llamar, por ejemplo, mediante la línea de órdenes:
![]() copyfile abc xyz
copyfile abc xyz
para copiar el fichero abc a xyz. Si xyz ya existe, se escribe sobre él. En caso contrario, se crea. El programa debe invocarse con dos argumentos, dados por dos nombres válidos de ficheros.
Los enunciados #include hacen que un gran número de definiciones y prototipos de funciones se incluyan en el programa. La línea siguiente es un prototipo de función para main, necesario para ANSI C.
El enunciado #define es una definición de macro para la cadena BUF_SIZE, el cual se expande en el número 4096. El programa leerá y escribirá en bloques de 4096 bytes.
El programa principal se llama main y tiene dos argumentos, argc y argv. Estos son proporcionados por el sistema operativo cuando se llama al programa. El primer argumento indica el número de palabras presentes en la línea de órdenes, que debe ser tres. El segundo es un vector de punteros a los argumentos. En este ejemplo de llamada los elementos de este vector contienen punteros a los valores siguientes:
![]() argv[0] = "copyfile"
argv[0] = "copyfile"
![]() argv[1] = "abc"
argv[1] = "abc"
![]() argv[2] = "xyz"
argv[2] = "xyz"
Mediante esta vía el programa tiene acceso a sus argumentos.
Se declaran cinco variables. Las dos primeras, src y dst, contienen los descriptores de fichero, son enteros pequeños asignados al abrir un fichero. Las dos siguientes, in y out son los contadores de bytes devueltos por las llamadas al sistema READ y WRITE respectivamente. La última, buf, es el buffer utilizado para almacenar los datos leídos, y proporcionar los datos a escribir.
La primera instrucción condicional verifica si argc = 3. Si no es así, se termina el programa con código de estado 1. Por convención, un código de estado distinto de 0 indica la aparición de un error. El código de estado es el único informe de error presente en este programa. Una versión comercial mostraría también mensajes de error.
Después se intenta abrir el fichero fuente y crear el fichero destino. Si el fichero fuente se puede abrir, el sistema asigna un entero pequeño a src, para identificación del fichero. Las llamadas al sistema posteriores deben incluir este entero, de forma que el sistema operativo sepa con qué fichero se desea trabajar. Análogamente, si se puede crear el destino, se le da un valor a dst para identificarlo. Si la apertura o la creación fallan, el descriptor correspondiente toma el valor -1, y el programa termina con un código de error.

Después viene el ciclo de copiado, el cual comienza leyendo los datos en bloques de 4K hacia buf. Esto se realiza mediante la función de biblioteca read, la cual utiliza la llamada al sistema READ. El primer parámetro especifica el fichero, el segundo el buffer, y el tercero el número de bytes a leer. La función read devuelve el número de bytes leídos (esto se guarda en in). Por lo general, este número es 4096, excepto en el caso de que en el fichero queden por leer menos de esos bytes. Cuando se llega al final del fichero, dicho número es 0. Si in es 0 o negativo, la copia no puede continuar, por lo que se ejecuta el enunciado break para finalizar el ciclo (que de otro modo continuaría de forma indefinida).
La llamada a write hace que el contenido del buffer pase al fichero destino. El primer parámetro identifica al fichero, el segundo al buffer, y el tercero indica el número de bytes a escribir, de forma análoga a read. Observe que el número de bytes que realmente se leen está dado por el contador de bytes, y no por BUF_SIZE. Esto es importante, puesto que el último buffer no será de tamaño 4096, a menos que el fichero tenga una longitud múltiplo de 4K.
Después de procesar todo el fichero, la siguiente llamada hace in = 0, con lo que se sale del ciclo. En este punto, se cierran los dos ficheros, y el programa finaliza con un código que indica su conclusión normal.
El ejemplo cliente servidor
En este punto se presenta una visión general de un servidor de ficheros, y un cliente que solicita sus servicios para copiar un fichero. Ambos programas están escritos en C. El cliente y el servidor deben compartir algunas definiciones, éstas se reunen en el fichero header.h, que se muestra en la figura 4.19. Tanto el cliente como el servidor lo incluyen mediante el uso del enunciado:
#include <header.h>
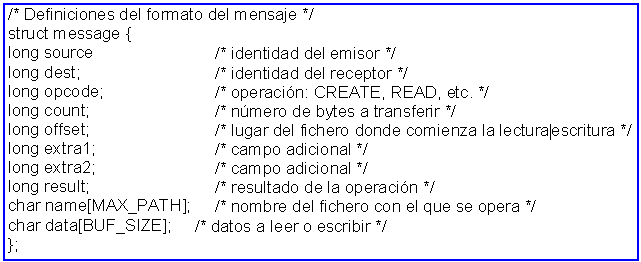
Analizaremos primero header.h. Empieza con la definición de dos constantes, MAX_PATH y BUF_SIZE, las cuales determinan el tamaño de dos vectores necesarios en el mensaje. El primero indica el número de caracteres máximo que puede tener una trayectoria de fichero (como /etc/passwd). El segundo fija la cantidad de datos que se pueden leer o escribir en una operación, al establecer el tamaño del buffer. La constante siguiente, FILE_SERVER, proporciona la dirección en la red del servidor de ficheros, de forma que los clientes le puedan mandar mensajes.

Figura 4.19. El fichero header.h que utilizan el cliente y el servidor.
El segundo grupo de constantes define los números de operación, necesarios para garantizar que el cliente y el servidor estén de acuerdo en el código que representará una operación. Aquí sólo se muestran cuatro, en un sistema real lo normal es que sean más.
Toda respuesta contiene un código de resultado. Si la operación tiene éxito, es frecuente que este código contenga información útil (como el número de bytes que se leen en realidad). Si no existe un valor por devolver (como cuando se crea un fichero), se emplea el valor OK. Si por alguna razón la operación fracasa, el código de resultado indica por qué, mediante códigos tales como E_BAD_OPCODE, E_BAD_PARAM, etc.
Por último llegamos a la parte más importante de header.h, la definición del propio mensaje. En nuestro ejemplo, es una estructura o registro de 10 campos. Todas las solicitudes del cliente al servidor utilizan este formato, al igual que lo hacen las respuestas. En un sistema real tal vez no se tenga un formato fijo (puesto que no se necesitan los campos en todos los casos), pero esto hace más sencilla la explicación. Los campos source y dest identifican al emisor y al receptor respectivamente. El campo opcode es una de las operaciones definidas antes; es decir, CREATE, READ, WRITE o DELETE. Los campos count y offset se utilizan como parámetros, y otros dos campos, extra1 y extra2, se definen para disponer de un espacio adicional en el caso de que el servidor se modifique posteriormente. El campo result no se utiliza en las solicitudes del cliente al servidor, se utiliza para devolver un resultado en las respuestas del servidor al cliente. Por último, tenemos dos vectores. El primero, name, contiene la trayectoria del fichero al que se accede. El segundo, data, almacena los datos que se envían de vuelta como respuesta a un READ, o los datos que se envían al servidor en un WRITE.
Analicemos ahora el código de la figura A.20. En a) tenemos el servidor; en b) el cliente. El servidor es directo. El ciclo principal comienza con una llamada a receive para obtener un mensaje de solicitud. El primer parámetro identifica a quién hizo la llamada, mediante su dirección, el segundo apunta a un buffer de mensajes donde se guarda el mensaje que llegará. El procedimiento de biblioteca receive realiza una llamada al sistema para que se bloquee el servidor hasta que llegue un mensaje. Cuando llega una, el servidor se desbloquea y se encarga del tipo de opcode. Para cada opcode se llama a un procedimiento distinto. Se dan como parámetros el mensaje de entrada y un buffer para el mensaje de salida. El procedimiento examina el mensaje de entrada, m1, y construye la respuesta en m2. También devuelve el valor del resultado en el campo result. Después de terminar send, el servidor vuelve a la parte superior del ciclo para ejecutar receive y esperar a que llegue el siguiente mensaje.
En la figura 4.20 b) se ve un procedimiento para copiar un fichero utilizando el servidor. Su cuerpo consta de un ciclo que lee un bloque del fichero fuente y lo escribe en el fichero destino. El ciclo se repite hasta copiar todo el fichero fuente, lo cual se indica mediante un código de retorno de lectura nulo o negativo.
La primera parte del ciclo se encarga de construir un mensaje para la operación READ y enviarla al servidor. Después de recibir la respuesta, se entra en la segunda parte del ciclo, que toma los datos recién recibidos y los envía de vuelta al servidor en un WRITE al fichero destino. Los programas de la figura 4.20 son únicamente un bosquejo del código. Se han omitido muchos detalles. Por ejemplo, no se muestran los procedimientos do_xxx y no se realiza una verificación de los errores. Aún así, debe quedar clara la idea de la interacción del cliente y el servidor.

Fig 4.20 .Ejemplo Cliente_Servidor.
Del código del servidor se deduce que solamente puede atender a una petición a la vez. Si el servicio de una petición es muy lento, porque, por ejemplo, precisa realizar entradas/salidas, se pueden demorar las solicitudes de otros clientes. Una solución, en un sistema operativo que posea el concepto de hilo, es que el servidor al aceptar una petición cree un hilo para que la sirva, siendo éste el responsable de contestar al cliente. Así se pueden atender varias solicitudes concurrentemente, un hilo pueden aprovechar las E/S de los otros hilos para ejecutar su código. Hay que decir que algunos sistemas operativos no permiten la creación dinámica (en tiempo de ejecución) de hilos, y de estar permitida existe un máximo de hilos por proceso. Si la creación es estática (en tiempo de compilación), se pueden crear, por ejemplo, 5 hilos, y que cada uno reciba una solicitud, la tramite y responda a ella.
En este apartado, y en los dos siguientes, vamos a exponer tres ejemplos clásicos de
sincronización entre procesos, proponiendo su solución utilizando semáforos. El problema de los productores y los consumidores ejemplifica la sincronización de varios procesos "productores" y "consumidores", los procesos de un grupo controlan tanto el progreso de los procesos de su grupo como los del otro grupo.
Especifiquemos el problema. Un conjunto de procesos "productores" y un conjunto de procesos "consumidores" se comunican entre sí a través de un buffer, en el que los productores van depositando elementos, y del cual, los consumidores los van sacando. Los productores llevan a cabo de forma continua un ciclo "producir un elemento - guardar el elemento en el buffer", y los consumidores repiten un ciclo parecido: "sacar un elemento del buffer - consumir el elemento". Un productor típico puede ser un proceso de tipo computacional que vaya colocando líneas de resultados en un buffer, mientras que el consumidor correspondiente puede ser el proceso que imprime estas líneas. El buffer tiene una capacidad limitada, pudiendo almacenar sólo N elementos del mismo tamaño. La sincronización que se requiere en este caso es doble: en primer lugar, los productores no pueden colocar elementos en el buffer si éste está lleno, y en segundo lugar, los consumidores no pueden sacar elementos del buffer si éste está vacío.

Además, el buffer y las variables compartidas deben protegerse del acceso concurrente por parte de los distintos procesos, pues son zonas compartidas de memoria modificables por los procesos. De ahí que el acceso al buffer y a las variables compartidas se realice en exclusión mutua.
La solución que se presenta utiliza un buffer circular, cuyos elementos son enteros, dos variables compartidas, que controlan dónde insertar o sacar elementos del buffer, y tres semáforos. Los programas se expresan en un lenguaje similar a C.
La sincronización se logra mediante los semáforos espacio y elementos, la exclusión mutua mediante el semáforo exmut. El operador % realiza la operación módulo (resto de la división entera).