
4.2.3 Semáforos
[DEIT93] [MILE94]
Tanto la solución de Peterson como la que emplea la instrucción TSL son correctas, pero adolecen del defecto de tener que utilizar espera ocupada. Esencialmente, lo que hacen estas soluciones es lo siguiente: inmediatamente antes de entrar en sus regiones críticas, los procesos comprueban que les está permitido; si no es así, se quedan en un bucle de espera hasta que puedan entrar.
Este mecanismo no sólo malgasta tiempo del procesador, sino que también puede producir efectos inesperados. Considérese una computadora con dos procesos; uno, H, de alta prioridad; y otro, L, de prioridad inferior. Las reglas de planificación (ver tema) hacen que se asigne el procesador a H siempre que esté listo para ejecución. En un instante dado, L estará dentro de su región crítica y H pasará a estar listo para ejecución. H comenzará ahora a realizar una espera activa, pero, dado que L no obtiene nunca el procesador mientras H esté ejecutándose, L nunca podrá salir de su región crítica, así que H se quedará para siempre esperando.
Podemos emplear unas primitivas de comunicación entre procesos que, en lugar de malgastar tiempo de procesador cuando un proceso no puede entrar en su región crítica, bloquean la ejecución del mismo. Una de las parejas más simples de primitivas son DORMIR (sleep) y DESPERTAR (wakeup). DORMIR es una llamada al sistema que bloquea al llamador, es decir, suspende su ejecución hasta que otro proceso lo despierta. La llamada DESPERTAR tiene como parámetro el proceso que se debe despertar.
El problema del productor-consumidor (con un buffer finito) servirá para ilustrar el uso de estas primitivas. Especifiquemos el problema. Un conjunto de procesos "productores" y un conjunto de procesos "consumidores" se comunican entre sí a través de un buffer, en el que los productores van depositando elementos, y del cual, los consumidores los van sacando. Los productores llevan a cabo de forma continua un ciclo "producir un elemento - guardar el elemento en el buffer", y los consumidores repiten un ciclo parecido: "sacar un elemento del buffer - consumir el elemento". Un productor típico puede ser un proceso de tipo computacional que vaya colocando líneas de resultados en un buffer, mientras que el consumidor correspondiente puede ser el proceso que imprime estas líneas. El buffer tiene una capacidad limitada, pudiendo almacenar sólo N elementos del mismo tamaño. La sincronización que se requiere en este caso es doble: en primer lugar, los productores no pueden colocar elementos en el buffer si éste está lleno, y en segundo lugar, los consumidores no pueden sacar elementos del buffer si éste está vacío.
Además, el buffer y las variables compartidas deben protegerse del acceso concurrente por parte de los distintos procesos, pues son zonas compartidas de memoria modificables por los procesos. De ahí que el acceso al buffer y a las variables compartidas se realice en exclusión mutua.
Los problemas comienzan cuando el productor quiere dejar algo en el buffer, pero éste ya está lleno. La solución es mandar a dormir al productor y despertarlo sólo cuando el consumidor haya retirado uno o más elementos. Análogamente, debe enviarse a dormir al consumidor cuando trate de retirar un elemento del buffer y éste esté vacío. Más tarde, cuando el productor deje uno o más elementos en el buffer, despertará al consumidor (ver figura 4.1).
Sin darnos cuenta, nos hemos metido en la boca del lobo. Para llevar la cuenta del número de elementos en el buffer, necesitamos una variable, cuenta. El acceso a la variable cuenta no está controlado. Así, se puede presentar la siguiente situación: el buffer está vacío y el consumidor acaba de leer 0 de la variable cuenta. En este instante el planificador decide pasar el control del consumidor al productor. El productor deja un elemento en el buffer, incrementa cuenta y observa que su valor ahora es 1, por lo que deduce que su valor era 0 y que, por tanto, el consumidor está dormido, así que el productor llama a despertar para despertar al consumidor.
Por desgracia, el consumidor no está todavía lógicamente dormido, de modo que la señal para despertarlo se pierde. Cuando el consumidor se active de nuevo, comprobará el valor de cuenta que leyó anteriormente, verá que es 0 y se irá a dormir. Por su parte, el productor acabará llenando el buffer y también se tendrá que ir a dormir. Ambos dormirán eternamente.
Fig 4.1 Solución equívoca al problema del productor-consumidor mediante dormir-despertar
Para solucionar este problema, Dijkstra, en 1965, tuvo la idea de utilizar una variable entera para contar el número de señales de despertar puestas "en conserva" para uso futuro. Propuso el tipo de variable llamada semáforo junto con las operaciones wait y signal definidas sobre él. En el artículo original sobre los semáforos Dijkstra utilizó las letras P y V, que son las iniciales de estos términos en holandés. Nosotros utilizaremos wait y signal por ser más descriptivos.
Un semáforo es una zona de memoria compartida que almacena un entero no negativo sobre el cual sólo puede actuarse con una de las operaciones siguientes:
![]() Inicialización: Un semáforo sólo puede inicializarse una vez, normalmente en el momento en que se define. Nosotros representaremos la inicialización como 's ¬ x', donde s es el nombre del semáforo y x es un entero no negativo.
Inicialización: Un semáforo sólo puede inicializarse una vez, normalmente en el momento en que se define. Nosotros representaremos la inicialización como 's ¬ x', donde s es el nombre del semáforo y x es un entero no negativo.
![]() wait(s): Si s > 0 decrementa s en una unidad. Si s vale 0 provoca el bloqueo del proceso hasta que otro proceso realice una operación signal sobre s. Si existen varios procesos bloqueados en un semáforo, sólo uno de ellos podrá pasar a listo tras una operación signal sobre él. No se lleva a cabo suposición alguna sobre cuál de los procesos bloqueados será el elegido.
wait(s): Si s > 0 decrementa s en una unidad. Si s vale 0 provoca el bloqueo del proceso hasta que otro proceso realice una operación signal sobre s. Si existen varios procesos bloqueados en un semáforo, sólo uno de ellos podrá pasar a listo tras una operación signal sobre él. No se lleva a cabo suposición alguna sobre cuál de los procesos bloqueados será el elegido.
![]() signal(s): Si no hay procesos bloqueados en s, provoca el incremento de s en una unidad. Si hay procesos bloqueados en s (que valdrá cero), provoca la transición a listo de uno de estos procesos.
signal(s): Si no hay procesos bloqueados en s, provoca el incremento de s en una unidad. Si hay procesos bloqueados en s (que valdrá cero), provoca la transición a listo de uno de estos procesos.
Además, las acciones que implica una operación wait o signal se ejecutan indivisiblemente. Esto es crucial para garantizar la coherencia del semáforo, ya que éste no es más que una variable compartida. Como se vio, una zona compartida de memoria no puede ser accedida concurrentemente por más de un proceso, si al menos uno de ellos la modifica. Volveremos sobre este tema en breve.
Una posible implementación de los semáforos
Como se ha comentado, los mecanismos de comunicación entre procesos son servicios del sistema operativo. La implementación de wait y signal se va a realizar como rutinas de servicio a interrupción. La operación wait lleva implícita la idea de que los procesos se quedan bloqueados cuando un semáforo tiene el valor 0, y son liberados cuando se realiza una operación signal. La forma natural de implementar todo esto es asociando a cada semáforo una cola. Cuando un proceso lleva a cabo una operación wait sobre un semáforo a cero, se añade a la cola del semáforo y se le pasa a estado bloqueado. Recíprocamente, cuando se ejecuta una operación signal sobre un semáforo determinado, se saca un proceso de la cola del mismo (a menos que esté vacía) y se le hace listo. Un semáforo debe implementarse, pues, a base de dos elementos: un entero y un puntero asociado a una cola (que puede ser nulo).

No hemos dicho nada aún acerca del proceso que será sacado de la cola del semáforo después de una operación signal. Tampoco hemos dicho nada sobre el lugar donde hay que colocar un proceso que haya efectuado un wait sobre un semáforo a cero. Para la mayoría de semáforos es adecuada una cola en la que se siga el criterio de que el primero en entrar sea el primero en salir (FIFO), ya que con ello se garantizaría que todos los procesos bloqueados puedan eventualmente hacerse listos. Lo que es importante tener en cuenta es que distintos semáforos pueden estar asociados a colas con criterios distintos. Ello obliga a añadir un nuevo elemento en la implementación de un semáforo con el fin de especificar el criterio de gestión de la cola. Este elemento puede ser un puntero a un pequeño programa que lleve a cabo las funciones de entrada y salida de la cola.
Indivisibilidad
Como se apuntó más arriba tanto wait como signal deben ser operaciones indivisibles, en el sentido de que sólo un proceso debe poder ejecutarlas en cualquier momento. Justifiquemos dicho requisito de indivisibilidad. Supóngase que dos procesos, P0 y P1, desean realizar la operación signal(S) sobre el semáforo S que tiene el valor 3. Si el código expuesto más arriba no es indivisible, podría darse la circunstancia de que el procesador se cambiara mientras que un proceso ejecuta la instrucción 's ¬ s + 1'. Como esta instrucción de un lenguaje de alto nivel puede ser traducida por el compilador a las instrucciones en ensamblador que se apuntan en la siguiente tabla (donde 'LOAD A, S' carga el
con el contenido de la variable S, 'ADD A' incrementa el acumulador en una unidad y 'STO S, A' almacena en la variable S el contenido del acumulador)
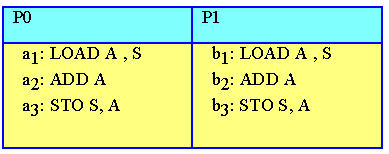
la ejecución de estas instrucciones en el orden a1b1b2b3a2a3 provocaría que S valiera 4, cuando debería valer 5. El problema básico es el mismo del ejemplo de la cuenta bancaria, P0 lee S, pero después trabaja con un valor local (3) distinto al valor actual (4).
Se presenta un problema análogo si dos procesos ejecutan simultáneamente una operación wait sobre un mismo semáforo, o si se ejecuta simultáneamente un wait y un signal.
Pasemos ahora a ver cómo puede lograrse la exclusión mutua en el código de wait y signal. Ambas operaciones deben implementarse como rutinas que empiecen con algún tipo de operación de bloqueo, y terminen con otra operación de desbloqueo. En una configuración consistente en un sólo procesador, la operación de bloqueo puede implementarse fácilmente inhibiendo el mecanismo de interrupción. Ello asegura que el proceso no puede perder el control del procesador central mientras esté ejecutando el wait o el signal, ya que no hay forma de que pueda ser interrumpido. La operación de desbloqueo se llevaría a cabo entonces, simplemente, volviendo a autorizar las interrupciones. En una máquina con varios procesadores centrales, este procedimiento no es adecuado, ya que es posible que dos procesos ejecuten de forma simultánea un wait o un signal trabajando sobre dos procesadores distintos. En este caso, el problema se solventa desactivando las interrupciones y encerrando el código de las operaciones en una exclusión mutua basada en la instrucción TSL, tal como se vio en el apartado de la exclusión mutua con espera ocupada. La utilización de la instrucción TSL implica una espera ocupada potencial si dos procesos quieren ejecutar simultáneamente, en procesadores distintos, una operación sobre un mismo semáforo. Sin embargo, como las rutinas wait y signal son muy simples, el tiempo de espera empleado en este ciclo de espera es corto.
Es conveniente destacar que las operaciones de bloqueo y desbloqueo implementadas mediante la instrucción TSL no pueden emplearse como sustitutas de los semáforos para implementar la exclusión mutua entre procesos. La espera ocupada no es aceptable para el tiempo que podría pasar un proceso esperando que acabe la sección crítica de otro proceso. Sin embargo, sí es aceptable para lograr la exclusión mutua de las operaciones sobre semáforos, pues estas tienen un código corto, esto se ilustra en la siguiente tabla
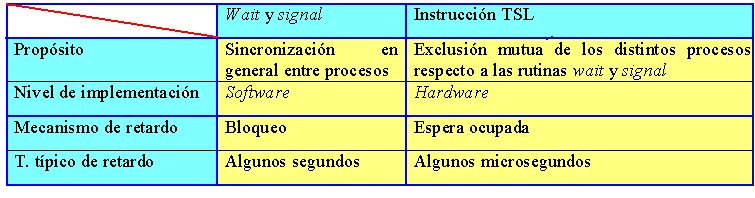
Fig 4.3. Utilización de semáforos para la Exclusión Mutua
Ejemplos de sincronización utilizando semáforos
Al principio del tema ya explicamos en qué consistía la sincronización. Un tipo particular de sincronización lo constituye la exclusión mutua, que puede ser lograda si los procesos colocan una operación wait justo antes de entrar en su sección crítica, y una operación signal inmediatamente después de su sección crítica sobre un mismo semáforo exmut cuyo valor inicial sea 1. Obsérvese que esta solución evita la espera ocupada.

Ejemplo 1
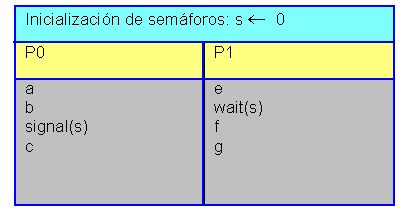
Dados los siguientes procesos, donde las letras representan pasos secuenciales:
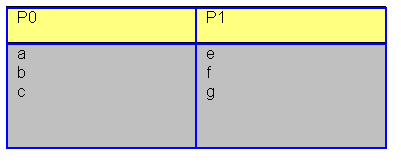
vamos a sincronizarlos de forma que el paso f de P1 no se pueda realizar hasta que P0 haya realizado el paso b. La solución es:
Ejemplo 2
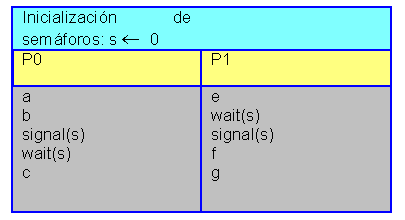
Dados los procesos del ejemplo anterior, vamos a sincronizarlos de forma que el paso f de P1 no pueda realizarse hasta que P0 haya realizado el paso b, y que el paso c de P0 no se pueda realizar hasta que P1 haya realizado el paso e. Este tipo de sincronización doble, en el que los dos procesos se sincronizan en un determinado punto de cada proceso se llama cita. Veamos como funciona el siguiente intento:
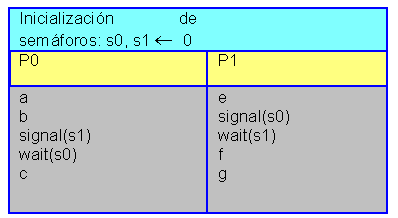
Esta solución no es correcta, si el proceso P1 llega a wait(s) antes de que P0 llegue a signal(s), la sincronización se produce, si no ocurre esto, la sincronización falla. El siguiente planteamiento sí funciona:
Por último, supóngase que un proceso desea que se le avise si ocurre un evento específico, y que algún otro proceso es capaz de detectar la ocurrencia de este evento. Este problema lo resolveríamos con la utilización de un semáforo tal y se muestra en la figura 4.4.
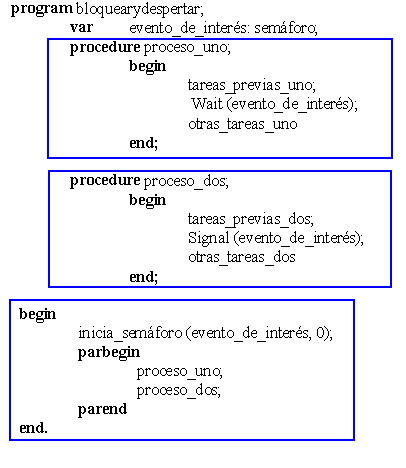
Fig 4.5 Ejemplo de sincronización con semáforos.
Deadlock (Interbloqueo)
Cuando varios procesos compiten por recursos es posible que se dé una situación en la que ninguno de ellos pueda proseguir debido a que los recursos que cada uno de ellos necesita estén asignados a otros procesos. Esta situación se conoce en inglés con el nombre de deadlock, nosotros utilizaremos el término interbloqueo. Otra definición de interbloqueo es la siguiente: "un conjunto de procesos se interbloquea si cada proceso del conjunto espera un evento que sólo puede ser provocado por otro proceso del conjunto".
Una situación que provoca un interbloqueo es la de varios procesos que tienen secciones críticas mutuamente excluyentes, para su ejecución en exclusión mutua adoptan la solución de utilizar un semáforo exmut inicializado a 1, tal como se vio un poco más arriba. Si un proceso ejecuta un wait(exmut) dentro de una sección crítica interbloquearía a todos los procesos que excluyen sus secciones críticas con exmut.

Veamos otro ejemplo, dos procesos, llamados P0 y P1, utilizan dos recursos no compartibles (tales como una impresora y un fichero abierto en modo de escritura) X e Y. Para proteger su uso concurrente se utilizan los semáforos x e y, en el modo antes descrito. Estúdiese los fragmentos de código de P0 y P1 mostrados más abajo. Ambos procesos quieren utilizar los dos recursos a la vez. Si primero se ejecuta el código de un proceso y después el del otro no hay ningún problema. Pero supóngase que tras realizar P0 el wait(x) se cambia el procesador a P1, si éste ejecuta wait(y) se producirá un interbloqueo. Es importante darse cuenta de que este error se producirá sólo para muy pocas ejecuciones (especialmente si estos fragmentos de código cálculos(2), cálculos(3), cálculos(5) y cálculos(6) son pequeños), pues va a depender del orden de asignación del procesador a los procesos (algo impredecible). Por lo tanto, estos errores son difíciles de detectar, y cuando ocurren, difíciles de depurar, pues para reproducir el error se debería dar una secuencia de planificación similar, y la secuencia de planificación dependerá de la carga del sistema.
Volviendo al ejemplo anterior del productor-consumidor veamos cómo también una mala programación nos llevaría a un interbloqueo. Supongamos que invertimos las operaciones wait en el código del productor, de forma que mutex se decrementa antes que vacio. Si el buffer está lleno, el productor se bloquearía, con mutex igual a 0. La próxima vez que el consumidor intenta acceder al buffer, realiza wait sobre mutex, y como vale 0, el consumidor también se bloquea.
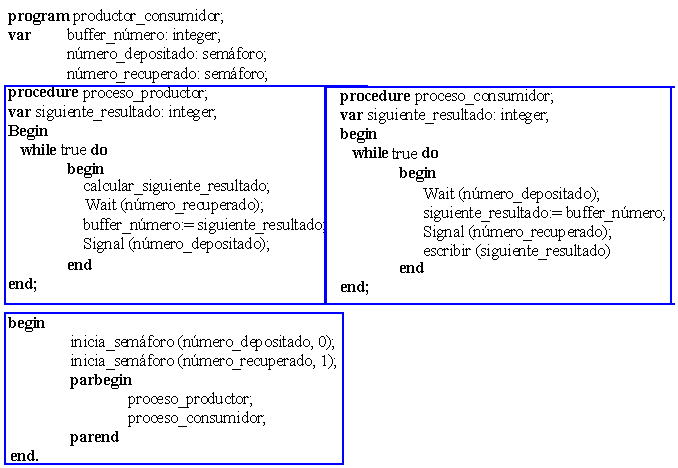
Fig 4.6. Productor-Consumidor con semáforos (buffer de un sólo elemento)
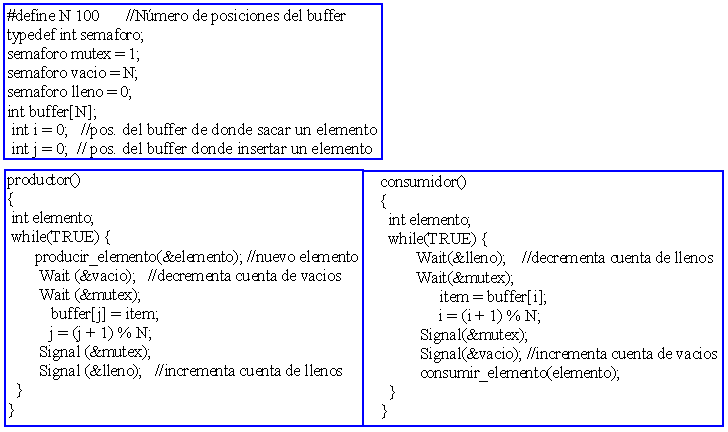
Fig 4.7. Solución al problema productor_consumidor con semáforos (buffer con N elementos)
Se llega a la conclusión de que la programación con semáforos debe realizarse con mucho cuidado para evitar los interbloqueos.
4.2.4 Monitores
[DEIT93] [MILE94]La programación mediante semáforos tiene el inconveniente de que es fácil equivocarse al utilizarlos; además, una equivocación de este tipo es difícil de detectar, pues sólo produce ejecuciones erróneas ocasionalmente.
Para facilitar la escritura de programas correctos, Hoare (1974) y Brinch Hansen (1975) propusieron una primitiva de sincronización de alto nivel, llamada monitor. Sus propuestas tenían ligeras diferencias, las cuales señalaremos a continuación. Un monitor es una colección de procedimientos, variables y estructuras de datos que se agrupan en cierto tipo de módulo o paquete. Los procesos pueden llamar a los procedimientos de un monitor cuando lo deseen, pero no se tiene acceso directo a las estructuras de datos internas del monitor desde un procedimiento declarado fuera de él. Para modificar las estructuras de datos internas del monitor es preciso utilizar los procedimientos definidos en él. El siguiente ejemplo ilustra un monitor escrito en un lenguaje similar a C.
Monitor ejemplo
{
int i;
condición c;
insertar(int item)
{
...
}
sacar(int *item)
{
...
}
}
Los monitores tienen una propiedad importante que los hace útiles para conseguir la exclusión mutua: sólo uno de los procesos puede estar activo en un monitor en cada momento. Los monitores son construcciones del lenguaje de programación, por lo que el compilador sabe que son especiales y puede controlar las llamadas a los procedimientos del monitor de manera distinta a las llamadas a los demás procedimientos. Por lo general, cuando un proceso llama a un procedimiento de un monitor, las primeras instrucciones de éste verificarán si hay otro proceso activo dentro del monitor. En caso afirmativo, el proceso que hace la llamada será bloqueado hasta que el otro proceso salga del monitor. Si no hay otro proceso que esté utilizando el monitor, el que hace la llamada podrá entrar.
El compilador es el responsable de conseguir la exclusión mutua sobre los datos del monitor, siendo usual que implemente dicha exclusión con semáforos, tal como se vio en el apartado anterior. En todo caso, el programador no es consciente del modo en que se logra tal exclusión, él sólo debe preocuparse de determinar los datos compartidos y las secciones críticas, y de situar todo esto en el interior del monitor. La responsabilidad de lograr la exclusión mutua es del compilador.
Sin embargo, los monitores no son tan sencillos de programar como parece a primera vista. Existe un problema que aún no se ha comentado. A veces es necesario que un proceso se bloquee dentro del monitor. Por ejemplo, en el problema de los productores y consumidores es posible que un productor se deba bloquear al intentar insertar y descubrir que el buffer está lleno. Si se bloqueara sin más, tendríamos un interbloqueo, pues ningún consumidor podrá entrar al monitor para consumir un elemento y producir un espacio.
La solución a este problema reside en la introducción de variables de condición, junto con dos operaciones sobre ellas, wait y signal. Si un procedimiento de un monitor descubre que no puede continuar (por ejemplo, cuando un productor encuentra el buffer lleno), ejecuta una operación wait sobre alguna variable de condición, como por ejemplo espacio. Esto hace que el proceso que entró en el monitor se bloquee. También permite que otro proceso que tenía prohibida la entrada al monitor pueda hacerlo ahora.
Este otro proceso, como por ejemplo, un consumidor, puede despertar a su compañero dormido con una instrucción signal, sobre la variable de condición que su compañero espera. Para evitar que existan dos procesos activos en el monitor al mismo tiempo, es necesaria una regla que indique lo que debe ocurrir después de signal. Hoare propuso que se permitiera la ejecución del proceso que ha despertado y que se suspendiera la ejecución del otro. Brinch Hansen propuso que un proceso que realizara una instrucción signal debería salir inmediatamente del monitor. En otras palabras, una operación signal debería aparecer sólo como última instrucción de un procedimiento del monitor. Nosotros utilizaremos la propuesta de Brinch Hansen. Si se ejecuta un signal en una variable de condición en la que están esperando varios procesos, sólo uno de ellos revive, siendo determinado éste por el planificador del sistema.
Las variables de condición no son contadores. No acumulan señales para su uso posterior, como hacen los semáforos. Así, si se hace un signal sobre una variable de condición a la que nadie espera, la señal se pierde. Wait debe aparecer antes de signal. En la práctica, esto no representa ningún problema puesto que un proceso puede verificar el valor de una variable de condición (esta operación no es realizable sobre semáforos) para ver si es necesario realizar un signal.
A continuación se muestra una solución al problema de los productores y consumidores utilizando monitores. En esta solución se utilizan los conceptos recién explicados. Está expresada en un lenguaje parecido a C.

Con la exclusión automática de las secciones críticas, los monitores hacen que la programación en paralelo tenga menos tendencia a los errores que en el caso del uso de semáforos. Sin embargo, pocos lenguajes de programación incluyen monitores, ejemplos de estos lenguajes son Concurrent Euclid y Modula 2.
Fig 4.8. Asignación de recursos mediante monitores
