Lecture 17 — Security I
June 1, 2009
By Devon Rifkin and Greg Jones
Introduction to Security in Computer Systems
It would be nice if everyone in the world got along. In reality, that's not the way the world works, and a lot of computers get misused. We have to complicate computer systems to prevent them from being misused. This complication contradicts much of what we have already learned, specifically goals of keeping the system simple, and with nice layers of abstraction. We'll find that security measures we take will violate levels of abstractions. It is a pain, but necessary.
Security in the Real World
Security is a concept that applies to many areas besides computers. It is about preventing and defending against attacks. Security generally falls under one of two categories:
- Protecting against attacks via force
Example: someone beats you up and takes your money
- Protecting against attacks via fraud.
Example: someone pretends to be a bank, takes your money, and then vanishes
In the end, all security is backed up by physical means. To actually completely stop email spam, you need to find and arrest the spammer. Computer security involves very technical measures, but should always map into a real world operation where the attackers get caught.
Attacks on Computer Systems
The two major kinds of attacks on computers are consistent with real world attacks:
- Force
Example: attacker walks away with your computer
- Fraud
Example: attacker sends packets, pretends to be your friend, takes your money
Generally the things that computers control are more valuable than the actual computers (e.g., bank account information, credit card info). For this reason, fraud is more dominant and more popular in the world of computer security.
Fraud Attacks
There are three major forms of fraud attacks. They can involve both software and hardware, but software is generally attacked more. The three forms are:
- Attack against privacy: unauthorized release of information
Example: attacker finds credit card number
- Attack against integrity: the attacker changes the state of your computer
Example: student tampers with database to change the student's grade
- Attack against service: the attacker tries to prevent your computer from working
Example: denial of service attack, which attempts to swamp your system so it's unusable
Another way to think of the first two attacks is that attack #1 is a read attack and attack #2 is a write attack.
We have to figure out ways of defending ourselves against all three problems. When devising defenses, we have three general goals:
- Performance: keep the system operating at an acceptable level (balance between performance and security)
- Deny/prevent unauthorized access: users shouldn't be able to read things they shouldn't be able to read, or write stuff they shouldn't be able to write
- Allow authorized access: in trying to achieve the two previous goals, a trivial approach would be to always say no. However, this would leave the system unusable; authorized access must be allowed.
There is a natural tension between goal 2 and goal 3. The more computer security features you attach to a computer, the less useful the computer becomes. An OS designer has to make design choices early on about the balance between these two goals. For example, the designers of Windows chose to favor goal 3, leading to a very insecure system. Other, now unknown systems focused more on goal 2. They were very secure systems, but were difficult to use and never gained popularity.
Threat Modeling
Suppose your job is to set up a new computer system. You have limited resources. You want your system to be secure, but you don't want to waste money defending against attacks that never come.
Threat modeling is an important task. If a designer does not have a threat model in their design document, chances are they have security problems.
You have to know your enemy and figure out how they'll attack. Otherwise, you won't focus in the correct areas.
Threats
- Insiders: similar to bank security threats. Insiders are the #1 threat to banks. More money is lost to bank fraud internally than bank robbers. This is also true of computer systems. A sizable fraction of computer security in any real system is protecting the system from insiders.
- Social engineering: Outsiders pretending to be insiders.
Example: Kevin Mitnick, a famous hacker, did not use fancy cryptography attacks. Instead, he broke into phone systems with social engineering. He called up the phone company, pretending to be a phone technician trying to fix a phone system. He would then request and receive passwords.
- Network attacks: viruses (spread originally by floppy, now email and more recently drive by downloads), botnets, server buffer overrun exploits.
- Device attacks: USB viruses (e.g., US Military in Afghanistan), CD-ROM
Security systems need to be devised to deal with these attacks.
Case Study: NFS and Security
Inside Linux
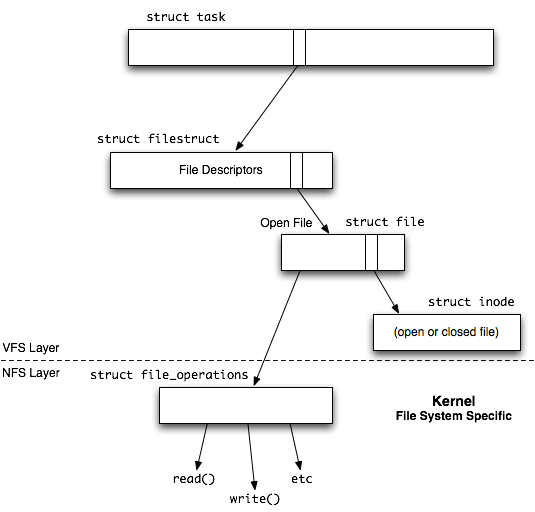
Each process contains a file descriptor, struct task, which points to everything having to do with a given process. The struct task points to an array of file descriptors, struct filestruct, which contains a pointer to a struct file for each open file. Each open file's struct file has a pointer to the file's struct inode. Finally, each actual file on the file system has a struct inode that points to it, whether it's open or not.
All of the aforementioned structures are contained in the VFS (virtual file system) layer of the file system. The NFS layer in the kernel contains the actual code with which to perform file operations and is file system specific (belongs to the file system). Each file in the VFS layer contains a pointer to a struct file_operations structure in the NFS layer. This structure contains pointers to operations such as open(), read() and write().
Internally Linux has built an object-oriented system, in which we can have different kinds of open and read or write calls depending on the filesystem. This separation between virtual and actual file system allows multiple types file systems to be mounted within the file system with no external change to user operation.
To mount a new file system, the user can simply use the system call mount():
mount(device, location_in_filesystem)In this case, the device would be something such as /dev/hda1, for example.
NFS Server in Action
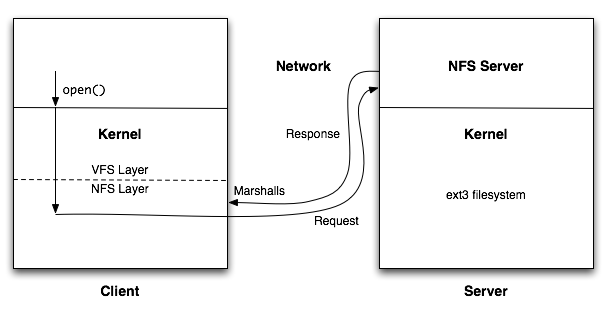
When an application running on the client makes a system call like open(), the syscall goes to the client kernel. The syscall is handled by the NFS layer, which marshalls the request and sends it over wire to the server. The server has a kernel and its own file system, but NFS does not care what the file system on the server actually is. When the marshalled open() request comes to the server, it unmarshalls it and opens the file in its own file system. In effect, NFS is an implementation of an RPC, which does not change how applications operate at all. All the work is being done inside the kernel.
It is important to note that all performance discussions (pipelining, etc.) from last lecture apply here as well. In particular, when there are a lot of reads and writes from the NFS, things will be very slow without caching and pipelining. However, the focus of this lecture is not performance, it's security. Looking at this from a security point of view, we have some problems. We need to make sure that the wrong guy can't access the files on the server. What prevents an attacker from sending some bogus packets across the network, giving him access to some files he shouldn't have access to?
NFS Concepts: Stateless vs. Stateful
NFS server protocol was originally stateless by design. In other words, no important state information is stored in the servers RAM. All important information is stored on the server's disk or another secondary storage device. This means the server survives reboots. The client will not care (and for that matter not even know, except for a brief slowdown) if the server reboots.
If the server is stateless, the client cannot lock up the server. If the server is stateful (maintains state), then the server is tracking clients, either for efficiency or for supporting more features, like locking. If you have a misbehaving client on a stateful server, your server will likely misbehave as well. For example, a client could lock a region of a file, then crash. The other clients would have to wait, but since the original client is dead, the file won't unlock. With the stateless approach, one client can't prevent other clients from getting work done. Robustness in the presence of client failures was the main reason NFS was initially designed as stateless.
File Handles
As far as security goes, we have to prevent server-client request-response pairs from colliding. An NFS file handle is a short, unique identification number for a file on the server. This handle is a relatively "small" number (< 256 bytes, for example). It uniquely identifies the file across on the server, survives file renames, and persists reboots. It is a property of a file itself, and not a filename. File handles are a corollary of a stateless server. A client can keep using a file handle that it received much earlier, and it will continue to work.
We now consider implementing a file handle on top of a UNIX server. We can use the files inode number added to the device it's sitting on. Now we have a unique file handle right? Almost, but there is something that isn't quite right. In UNIX, if you delete a file and create a new one, the two might have the same inode number. To fix this, UNIX also adds an incremental serial number (stored in the inode) to the file handle. This guarantees the file handle is unique and that NFS clients won't get confused by recreating files.
We can see in Figure 3 above that to do an open, we pass the request to the NFS server, which constructs a file handle and sends it back. To do read and writes, we use the given file handle. Open gives you file handles, and read or write uses them.
Have we already seen file handles in UNIX? They are very close to the idea of file descriptors, but not quite the same. The difference is that processes can share file handles, but not file descriptors. Twenty different processes can share the same file handle. They are ultimately meant for communication between kernels, not between applications.
NFS Security: One Little Problem
Consider several different clients, each with it's own collection of user IDs and usernames.
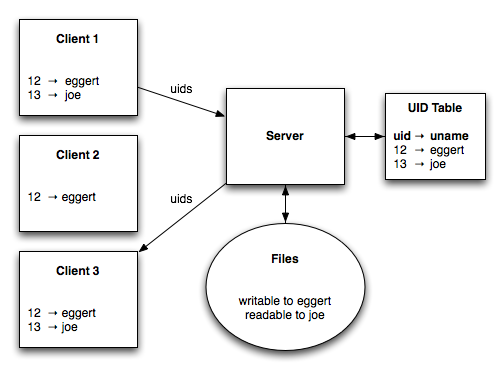
The user "joe" has an account on clients 1 and 3, but not on client 2. In contrast, eggert has an account on all three clients. The clients connect to a server that contains files owned by both eggert and joe. Associated with each file is a set of permissions. We need some way of enforcing these individual permissions, and the method we use has to work on each of the clients.
In original NFS, each file is associated with a number and an access control list. Requests and responses sent over the wire use only user IDs. That means this approach requires that all clients agree on the mapping between usernames and user IDs.
NFSv3, the most popular form of NFS these days, requires that the clients and the server use the same password database (at least to the extent that the uid-uname mapping must be shared).
The obvious fix to this limitation is to send usernames over the wire instead of user IDs. The downside of this approach is that names are larger and take up more space on the network. This approach is a little bit slower, but more flexible, and is supported by NFSv4. This is obviously not the only security problem in NFS, but it is a little problem indicative of the hassles that come up when you start dealing with NFS and security at the same time.
NFS Security: Authentication
Authentication provides much bigger problems for NFS security. Fundamental to the notion of security is that once you've authenticated yourself to the client, the the client trusts you. The client can start doing operations on your behalf with the server. The problem with this is that the weakest client controls security level of overall system. This means that NFS-like systems scale horrible, since they suffer from the weakest link situation. To counteract this effect, NFS and similar systems tend to be used in small protected environments, domains that are managed by a single set of sysadmins, for example.
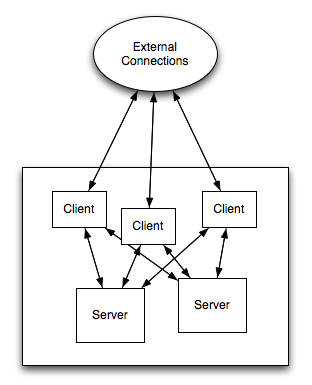
An example of an often used NFS environment consists of a server room with several NFS servers and clients. However, outsiders are not allowed to use NFS. It lives in a firewalled environment, and you don't have to worry about security as much. You still have to protect against remote access, but you don't have to worry about outsiders snooping in on the network. In this case, you also have to assume that people can't take over the clients on your machines. That is, the client operating systems are trusted. In summary, we have a well managed environment, we don't want NFS to introduce any more security problems than we already have.
Suppose we want to use NFS in a wider environment (over the Internet). We don't want to have millions of users, just a few hundred. Clients and servers will be widely separated. If we want to run NFS in this environment, what we've talked about so far doesn't work. It's easy for pirates to snoop packets and pretend to be a client.
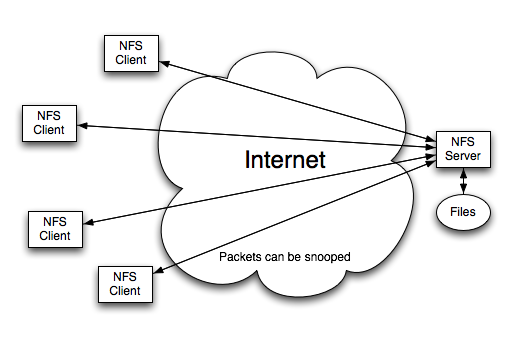
The clear solution to this approach is encryption. We have two options for how we want to attack this problem. On one hand, we could extend the NFS protocol to allow authentication for encryption (NFSv4 allows this). On the other hand, we could build a virtual private network (VPN) over the unsecured network (e.g., ssh, IPSEC). The idea is to build a model that emulates the "server room" environment, where everything is well managed and everyone is friendly. Either approach will work in theory. In practice, the performance of the second approach is terrible. In contrast the first approach is harder to manage, but overall performs better.
Security Mechanisms
In this section, we focus on mechanisms, not policy. Policy is what you're trying to implement. Mechanisms are the low level operations you need to implement the policy. Here are a set of important mechanisms:
- Authentication: how you determine whether a user is who they say they are. Many computer attacks operate via fraud, but authentication tries to prevent these attacks.
- Integrity: Make sure attackers are not able to silently modify data.
Example: using a checksum. If a file was modified, you'll know by comparing checksums.
- Authorization: keeps track of what people are allowed to do. Note the distinction between authorization and authentication: authorization is not concerned about stopping impostors. Authorization prevents actions not permitted by policy.
- Auditing: record the actions of any attackers. Do not necessarily prevent someone from breaking into the system, but record all of the damage. With the evidence, punish the guilty.
There are a set of constraints that must be applied to these mechanisms:
- Efficiency: has to run fast enough so people can continue to get their work done.
- Correctness: it is tempting to write a lot of security code, but the more you have, the less likely it is to be correct. Avoiding bugs is very important in security, because you're in an adversial environment. Attackers are actively trying to cause bugs to occur in order to exploit them.
Authentication
Authentication can be divided into two major categories:
- External authentication occurs when an outsider approaches your system and claims to be a specific user.
- Internal authentication occurs when a process acts on behalf of an already authenticated user.
We distinguish between the two, mainly for efficiency. External authentication schemes are often extensive, and would be too expensive to use internally — imagine using high quality crypto checking every time someone does a read or write. Internal authentication has to be fast; people perform a lot of internal operations.
External Authentication
Passwords are a popular form of external authentication. Users prove they are who they say they are with a login name and password.
Passwords are simple and easy to understand. However, it is easy to steal passwords. For example, attackers walk around LAX with video cameras and capture keystrokes.
There are other approaches:
- Public/private key: stored inside the disk. More resistant to snooping (shoulder spy-cam) attacks.
- Biometric: authenticates via thumb print scanner, retinal scanner, etc. Retinal authentication tends to work better because it is too easy for attackers to capture thumb prints.
- Shared-clock keys: a physical device that generates keys.
The best systems tend to combine two of these approaches. Any one of them has a weakness, but combining two or more tends to catch each other's weaknesses.
Internal Authentication
In Unix, each process descriptor contains the uid of the user the process is acting on behalf of. For this reason, changing a user's uid is a privileged operation. Using ps can show which uid a particular process is acting on behalf of.
When a Unix system boots, the very first process runs as root (uid 0). Eventually the system forks and lets you log in. If you supply the correct password, it changes the uid to yours. Since you are not root, the uid cannot be changed anymore.
There is a problem with this scheme. What if the user needs to perform an operation reserved for root (e.g., mount())? There has to be a way to become root again.
Two popular Unix commands are su and sudo, which let you run root privileged commands. How is this possible if changing the uid is also privileged? The answer: setuid programs.
File permissions have a bit called the setuid bit. If an executable has the setuid bit set in it, when it starts up it runs as the user who owns the file. If we have an executable owned by root and the setuid bit is set, it will run as root. This can be used to implement su or sudo. This file should be owned by root, and not writable by anyone else. Root trusts other people to run this program. For example, sudo refuses to do anything until the user types in the root password correctly.
We have "trusted code". This trusted code is su and sudo. We have to trust this code before we set the setuid bit. To maintain a secure system, we have to decide what code is trusted, and what isn't. On a Unix system, the find command can be used to find all of the trusted code; search for files with the setuid bit set.
Breaking Into a System
Suppose there's a bug in su, which is located at /bin/su . To fix this bug, the root user creates a new file called /bin/su.1 . The root user copies the corrected version of su to /bin/su.1 . The root user applies the appropriate permissions to the new file:
chmod 4755 /bin/su.1Finally, the user replaces su with su.1:
mv /bin/su.1 /bin/suNote that the root user used mv in an attempt to update su in a more atomic manner.
The Attack
Before the root user performs the above procedure, do the following:
ln /bin/su /home/eggert/bin/oldsuThe mv is in effect a call to rename: rename("su.1", "su"). This decrements the link count of su by one. Normally it will decrement to 0 and the file will disappear. However, the ln command in our attack increased the link count to 2. After the decrement, the link count becomes 1. The old version of su stays around even after the root user thinks they have gotten rid of it. The attacker can continue to use the old version and exploit the bug in it.