by Tim Hsieh, Chiachi Lo, Victor Renyu Zhu
One disadvantage of spinlocks is that they burn CPU on bottlenecks. To reduce this problem, we use blocking mutexes. This method reduces the CPU wait time by letting other processes run while the current process is being blocked. We are still burning CPU, but not as badly as before. This approach introduces a harder problem: deadlock.
Deadlocks occur when two or more processes hold different resources, and they all wait on each other to release the resources.
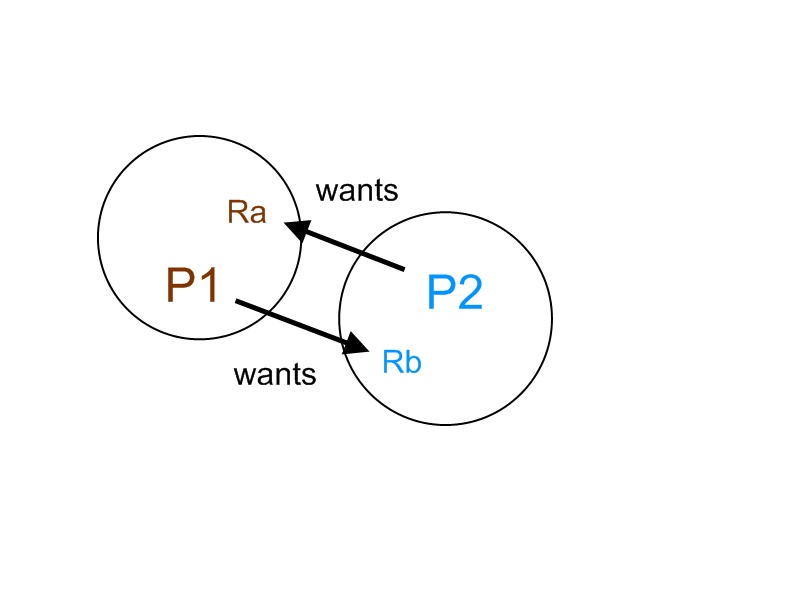
Example:
In the figure above, we have two processes P1 and P2, and two resources RA and RB. P1 has RA, but it wants RB, so P1 is waiting for P2 to release RB. P2 has RB, but it wants RA, so P2 is waiting for P1 to release RA. Both processes are waiting on each other and none of them release the resources. They both wait forever, and no useful work is done. This situation is a deadlock.
There are 4 conditions that must all be satisfied in order to have deadlock:
1) Circular Wait – In the example above, process p1 is waiting on process p2, which is waiting on process p1. A more complex example can be process p1 is waiting on process p2, which is waiting on process p3, which is waiting on process p1. The important idea is that there must be a loop within the chain of waiting.
2) Mutual Exclusion – The resource can only be owned by one process at any given time. For example, the mutex function we wrote in lab2 can only be owned by one process at a time. If there are unlimited amount of resources, then there would not be deadlock.
3) Process Must be “Greedy”- If process works by holding on to one resource while waiting on another process, then there can be deadlock. If the operating system requires the processes to release all of its resources before waiting on another resource, then there cannot be deadlock
4) No Preemption – Here, preemption means temporarily take the lock away from a process. If the operating system forcibly assigns resources to different process, then there can be no starving process. Therefore, no deadlock can occur.
To solve a deadlock, we only need to invalidate one of the above conditions. We cannot implement preemption because it would defeat the purpose of having a lock in the first place. We can make the process not “greedy”, but it might be less efficient. Some processes need multiple resources at the same time. By giving up existing resources to wait on another resource wastes the previous effort of obtaining it. We will focus on how to solve deadlock by detecting circular wait and other methods.
Plan
1. Make it impossible to have circular wait.
a) Approach 1: When the process calls the acquire function, the function can successfully acquire the lock, or it can return an error. When the acquire function fails, the process has the option to try again; however, it is not recommended. The process should do some useful computation if it fails.
b) Approach 2: “Lock
ordering”
We assign each lock a number, and each thread/process must obtain lock in
increase order. If one fails to acquire a lock, he must release all of his lock
and start over. The advantage is that it avoids/lessons convoy effect since no
process needs to wait for other process. In addition, it increases performance.
The downside is that if an uncooperative process does not follow this
convention, then there would still be deadlock. Therefore, this approach is
usually used in embedded system where all processes are cooperative.
2. Throw out mutual exclusion
We don’t want to do this because there are some resources that cannot be shared. See the bank account example from previous lecture: Bank Account Example
3. Acquire locks in sets
One can request all of locks at the same time. Then, when the locks are available at the same time, the process gets all of the locks. This is doable, but tricky to implement in O.S.
4. Manual Intervention
We can have an operator whose job is to kill the process that may go into deadlocks. Similarly, we can also set a timeout on our processes. If a process has stayed inactive for a long time, then our system can kill it.
Remember that pipe is a one way communication between two processes. By connecting two pipes across two processes, there can be two ways communication. This can create a deadlock when one process is waiting on the other to write a message, and the other one is waiting on the current one. In general, there might be deadlock when there are two pipes; however, there is an exception:
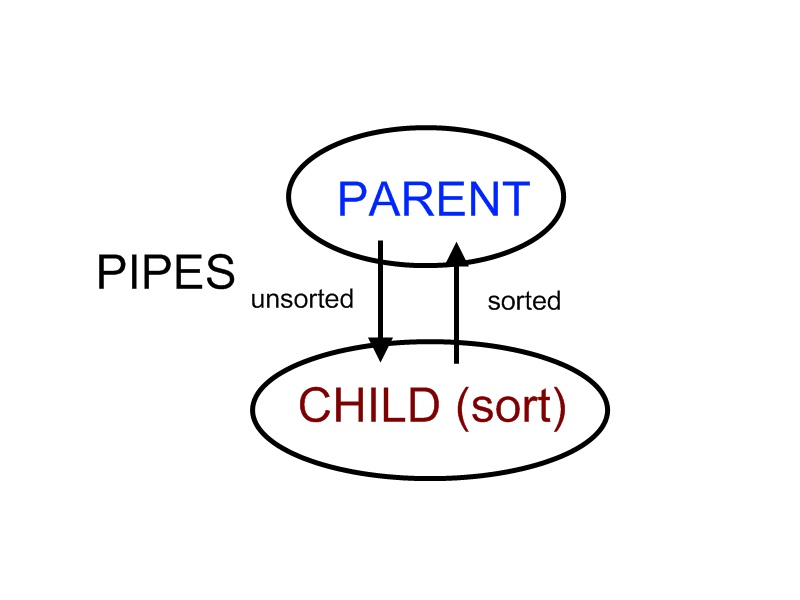
When we want to run a sort program, we fork a process and let the child process do the sorting. Parent process passes in unsorted data to the child through pipe. The child finishes sorting and sends the sorted data back to the parent through pipe. In this case, child process cannot do the sorting until parent process finishes passing in all of the data. Therefore, by the design of the algorithm, this system cannot deadlock.
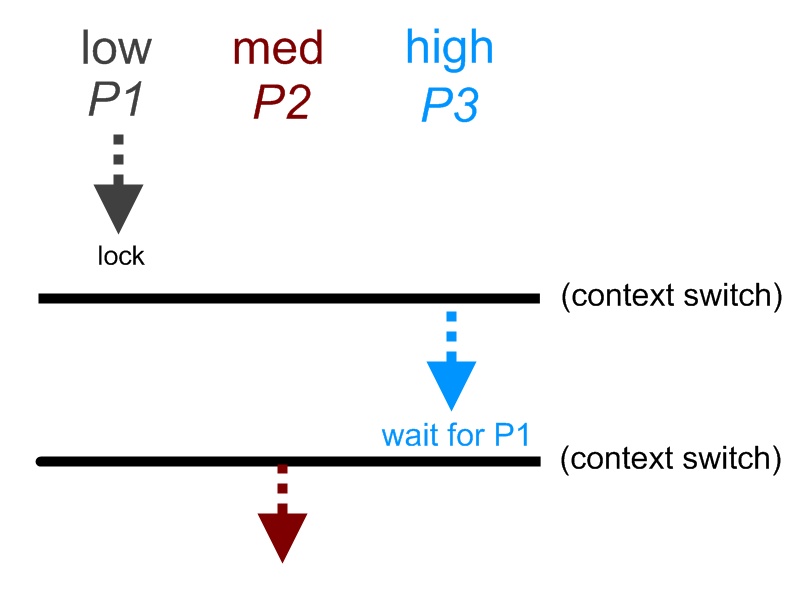
There is another form of deadlock that involves priority scheduling. This case is best explained through an example:
Suppose there are three threads running each with different priority level: low, medium, and high. Initially, only the low priority thread was running. The low priority process obtains has a lock, but a context switch occurred. The control is transfers to the high priority thread. This thread tries to acquire the lock that the lower priority process has; therefore, the higher priority thread is blocked because it is waiting on the lower thread. Mean while, another context switch occurs. The control transfers to the median priority thread. The median thread starts working. It can run for an arbitrarily long time because the higher thread is blocked, and it has higher priority than the lower priority thread. In this case, the higher priority process is being blocked and less priority process receives control. This situation is called "Priority Inversion". A graphical description is shown below:
A common way to solve this problem is to lend the priority of higher priority process to the lower priority process until the lower priority process finishes with the lock. This way, the higher priority process would not be blocked by lower priority process.
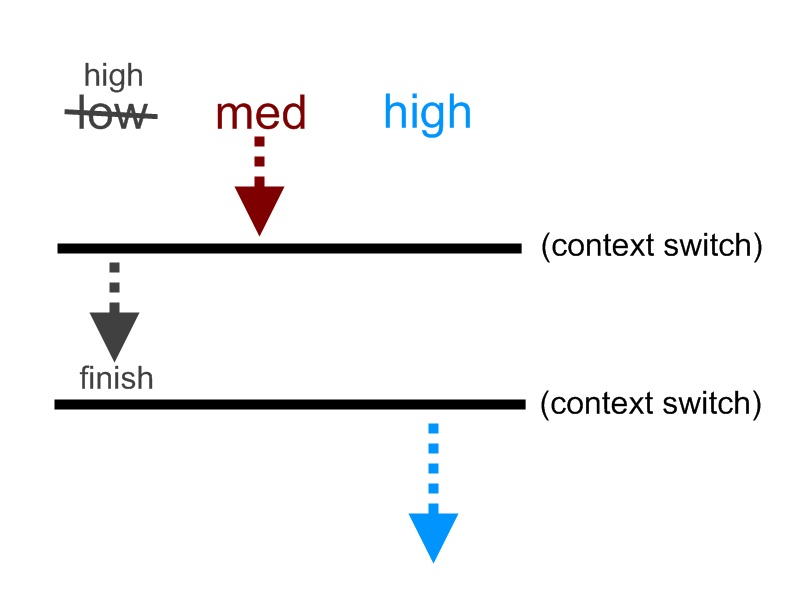
Note: this bug occurred in NASA’s Mars Pathfinder. For more information: please visit Mars Pathfinder Bug
To design a file system, we must first know what attribute our file system must have. In class, we came up with a list of desirable attributes for an ideal file system:
Looking at this list, one might remember that this list is very similar to the list used for database. So what is the difference? The only difference is that database indexes the files in the system whereas file system does not.
The trend of hard disk speed and CPU speed is shown below for comparison:
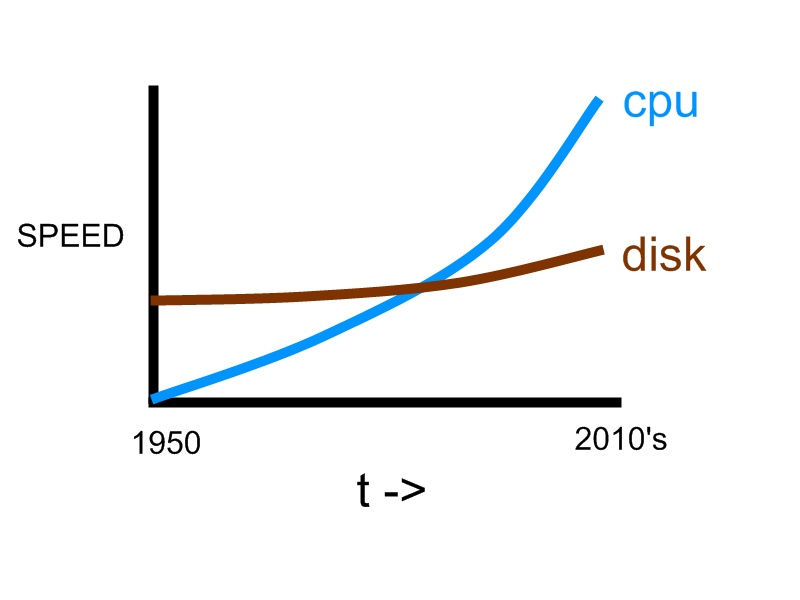
It is clear that when computer first came out, hard disk was considered to be extremely fast when compared to CPU. Over years, CPU speed grows exponentially, but disk speed cannot keep up. Eventually CPU’s speed greatly surpasses disk speed, making disk the bottleneck in a personal computer.
To understand how to design file system, we must understand more about the hardware that store the files: hard disk. In general, hard disk store information on a stack of splatter using magnetic properties of the platter. A disk head locates above the platter to read and write information onto the platter. In modern design, there are often multiple platters stack together. This design allow the information to be stored in cylindrical manner, reducing the need to move the disk head, thus improving the speed of the hard disk. The high level interface between hard disk and CPU is shown in the following graph:
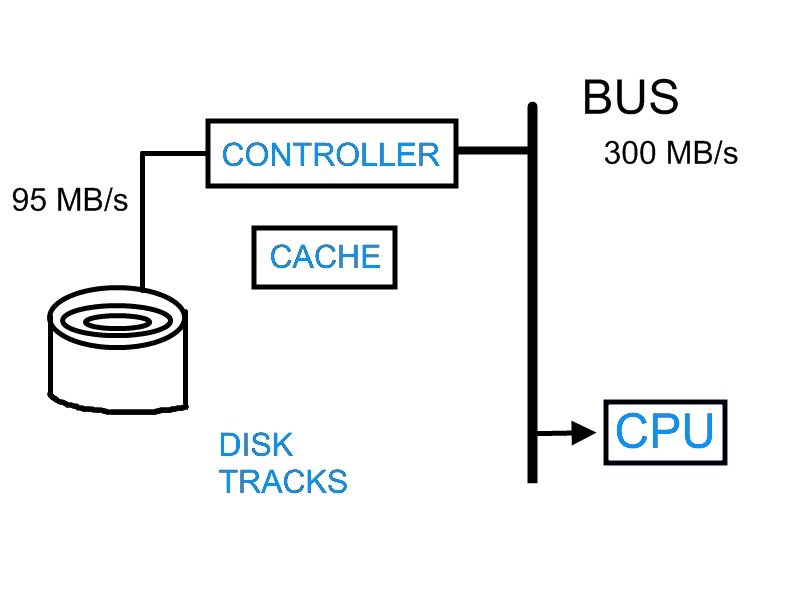
CPU sends requests to the controller of the hard disk. The controller processes the request and instructs the disk to spin to a certain location. Then, the information is send back to CPU via a bus. Controller would store some information inside cache. Therefore, the next time CPU requests the same information, the controller does not need to search through the hard disk again.
The following is a list of common specifications of a hard disk and their definitions:
Professor Eggert gave two examples of the real world hard disk specification. They are shown below:
| Seagate Barracuda LP (low power) | Segate Barracuda ES.2 | |
| External Transfer Rate | 300 MB/s | 300 MB/s |
| Sustained Data Rate | 95 MB/s | 116 MB/s |
| RPM Spindle Speed | 5900 rpm | 7200 rpm |
| Average Latency | 5.5 ms | 4.16 ms |
| Average Read Seek | N/A | 8.5 ms |
| Average Write Seek | N/A | 9.5 ms |
| Cache | 32 MB | 16 MB |
| Contact Start-Steps | 50,000 | N/A |
| Read Error Rate (non recoverable) | 1 x 10-14 | N/A |
| Capacity | 2 TB | 1 TB |
| AFR Annualized Failure Rate | 0.32 % | 0.70% |
| Power: | ||
| Operating | 6.8 W | 12 W |
| Idle | 5.5 W | 9 W |
To calculate the amount of time needed to transfer one byte from hard disk to program, we do the following calculation:
Task: Read at random from ES.2
| move read head | 8.5 ms |
| rotational latency | 4.16 ms |
| transfer data* | 0.07 ms |
| total time | 12.73 ms |
*Transfer Data is calculated by: 8192 (bytes) / 116000000 (bytes/sec) ~= 0.07 ms/byte. In this example, we assume that the program does one byte computation.
This total is an appalling number! Consider that a typical CPU today can do 2 x 10^9 instructions per seconds. This translates to about 25 million instructions!!! This means whenever we read from hard disk, the CPU does not do any useful work.
This terrible imbalance can also be seen from the following code. The amount of time used to execute each instruction is listed below:
| 8192 bytes | 16384 bytes | |
| for(;;){ | ||
| char buf[8192]; | ||
| read(buf); | 13 ms | 13 ms |
| compute(buf); | 1 ms | 2 ms |
| write(buf); | 14 ms | 14 ms |
| } | ||
| Total: | 28 ms | 29 ms |
| Rate: | 293 kb/sec | 565 kb/sec |
From the example above, it is clear that most of the time is spent on I/O operations rather than useful computation. The working speed of this program is 8192 bytes / 28 ms = 293 k bytes/sec. To ameliorate this problem, we can double the amount of buffer read. This means we would have 16384 bytes / 29 ms = 565 k bytes/sec, doubling the performance. While this improvement is nice, the situation is still terrible because our CPU can execute millions instructions during this period. We want to avoid CPU waiting while I/O operations occur.
The solution is batching, which we will talk about in the next lecture.